
July 2012
The goal of the EDRM XML schema is to provide a standard file format that enables an efficient, effective method for transferring data sets from one party to another and from one system to another in pursuit of electronic discovery (e-discovery) related activities.
Introduction
Exchanging data during e-discovery can be, and often is, problematic. More specifically, data exchanges can be costly in terms of time and money. Attorneys may not specify production formats (e.g., PDF, TIFF or native) or they may fail to request what type of load file should be used. (A load file helps import the data set into the case management, discovery management or e-discovery system.) There are different, proprietary load file formats for each system, so specifying which one you need can save quite a bit of time.
Compounding this problem, cases often involve more than two parties, with each party potentially using different systems. With a greater number of parties needing access to the data, the likelihood of problems in the exchanging of data goes up, especially if production and load file formats have not been specified. How much efficiency could be gained if all the parties could all exchange discovery ESI the same way, using established standards?
This paper will examine the problem of data exchange and sharing, then discuss how the EDRM XML load file format, along with good communication between parties, can add efficiency and accuracy to the process and help contain costs.
The Problem
When the first case and discovery management systems were created, most documents were stored in paper format. The documents themselves were the most important pieces of data and there was a limited amount of information about the documents that was relevant or necessary. During discovery, the documents were microfilmed, photocopied, or, more recently, scanned to TIFF images. TIFF images are also often put through an OCR (optical character recognition) process to make them text-searchable, which results in an additional TXT file containing the actual text.
These new systems were databases containing objective and subjective information about the documents and eventually relevancy and privilege calls as well. To help facilitate exporting and importing the resulting data sets between systems, load files were created. These delimited formats list each document in the set and the corresponding fields containing whatever additional data goes with it.
As the world has become almost exclusively electronic, data sets have become more complex. Information may not reside in a document at all, but in an email, instant message or database. This gave rise to a new term: electronically stored information (ESI). It also saw growing awareness in legal circles of the concept of metadata — the information about the data, like the creation and modified dates, when and to whom it was sent, and who created and modified it — that is often as important as, or sometimes even more so that, the data itself. This means that each piece of data, whether or not it is a “document,” may need to be transferred. It no longer is safe to assume that producing an image file suffices.
No less significant than this increase in complexity of data is the steep increase in the volume of data. E-discovery today can involve huge amounts of ESI, with cases involving thousands or even millions of documents . Typically each file to be produced first is processed, indexed, searched, and tagged, with all that information going in a database along with the related metadata. The load files that worked so cleanly for paper documents have become cumbersome and limiting when used in this context.
The very systems designed to make managing data sets easier have actually added another level of complexity. Two systems dominated the early market, but today there are now many choices for such software, each with a different load file format. They may have different delimiters and field names, use different encoding (e.g., ASCII or UTF8), or use different date and time conventions. Some of the software vendors have developed proprietary translators to try to ingest data from the other vendors, but as any litigation support person will attest, that doesn’t ensure an error free import.
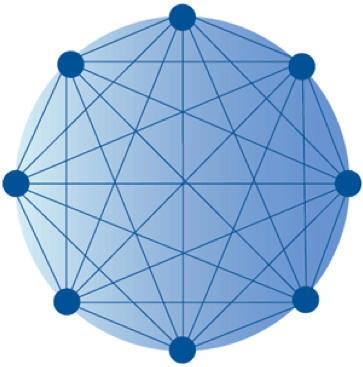
Adding to the disparate systems issue is the potential for a single case to involve multiple plaintiffs, defendants and third parties. In these situations, often each party has its own inside and outside counsel, review firms, and other specialty vendors assisting with the matter, and each of those organizations may need all or part of the data set.
Imagine each of these entities as a point on a circle. Data potentially will need to be sent from any one of these points to every other point. If that were not complicated enough, it now is possible for each point to be using a different system with a different load file format. The larger the case, the more points the circle can have and the more systems that can be involved.
Examining an excerpt of a load file conveys a better understanding of the challenges of importing data using the legacy, delimited formats. The following excerpt shows an entry for a single data element, an email in this example, from a standard Comma Separated Values (CSV) load file.
CSV Load File Example
"SAMPLE-0000001","SAMPLE-0000002","4075","\\Sample Data_09_28_2011@12-38-08PM\SAMPLE0001\IMG_0001\00000000051205B956AA854CAC5F68870D78B0AB84492600.msg","4","John Doerr <jdoerr@kpcb.com>","'larry_kanarek@mckinsey.com' <larry_kanarek@mckinsey.com>; 'kenneth.lay@enron.com'<kenneth.lay@enron.com>; 'blev@stern.nyu.edu' <blev@stern.nyu.edu>; 'jbneff@wellmanage.com'<jbneff@wellmanage.com>; 'hadlow@blackstone.com' <hadlow@blackstone.com>; 'rick.sherlund@gs.com'<rick.sherlund@gs.com>; 'jstiglitz@brookings.edu' <jstiglitz@brookings.edu>; 'hal@sims.berkeley.edu'<hal@sims.berkeley.edu>; 'corsog@sec.gov' <corsog@sec.gov>","John Doerr <jdoerr@kpcb.com>","","Garten Commission","\zl_lay-k_000.pst\lay-k\All documents","11/20/2000 3:38 AM","Microsoft Outlook\r\nMessage File","","","6/19/2010 6:21 PM","11/20/2000 3:38 AM"
Now imagine that there are entries like this for every email and document in a case. In a perfect world, you would know exactly which product and product version the load file was created with, what delimiter was used, and what fields were included, but according to Robert Gooch, Database Management Supervisor of Client Technology Solutions at Faegre Baker Daniels, LLP, this is not often the case.
Gooch states that common problems with legacy load files include malformed data, like inconsistent value separators or inconsistent date and time values (some systems store time and date information as text strings, where others normalize to U.S. or international standards like mo/day/year and day/mo/year). Such unresolved problems can include erroneous records, failed data loads and incorrect document breaks, all of which generate additional time and money requirements. If there is a problem with the time and date format of some entries, finding and correcting it can take a considerable amount of time. If commas are supposed to be used as the column delimiter, but there are also commas separating email addresses in the relevant email fields and the field is not quoted appropriately, finding and fixing that problem also can be a time-consuming process.

Beyond malformed data issues, legacy load files offer no way to transmit group or family data (e.g., near or exact duplicates, a series of document versions, or redacted documents) and only limited ways of transmitting metadata. There is no standard way this problem is addressed using legacy load file formats. One approach, not entirely satisfactory, is to include yet another file, often another delimited file, to help interpret that additional data. The problems that flow from this rigidity will continue to compound as the complexity and diversity of data types increases.
Creating a Standard
EDRM founders George Socha, Esq., and Tom Gelbmann realized that a standard, universally accepted load file format could make exporting and importing data much easier. Having a standard would eliminate issues around inconsistent delimiters or malformed data because everyone would be using the same standard.
Going back to the idea of points around a circle, what would a standard load file format do for the exchange of information? Again, if we imagine each party involved in the case as a point along the circle, using a single load file format improves the chances of being able to send and receive data sets that are consistently and reliably importable, regardless of the system used.
With this vision, Socha and Gelbmann evaluated the technology options for the format. The legacy, proprietary formats have no structure and aren’t extensible. According to Socha, “CSV has no structure. We needed something more controllable that allowed for things like definitions and descriptions.”
The XML Solution
Extensible Markup Language (XML) offered interesting and significant advantages over traditional delimited formats. It is an open standard with broad adoption around the world and was specifically created for the transporting of data between applications. It is platform and application independent, meaning every system can read and write to it consistently. It also supports Unicode, making it equally usable in any country and language.
Unlike the legacy load file formats, XML is truly extensible and completely self-describing. This means the markup describes the structure, type and names of the data it contains. It can represent everything needed to process the content of the data set without requiring additional files. Information like metadata, near and exact duplicates, whether or not it is redacted and why, parent/child relationships and more all can be conveyed cleanly through the XML format.
Consider the example EDRM XML load file below. It details the same email as the CSV example, but notice how the nested structure and color coding makes it much easier to read (this view shows the XML file in a web browser). Each tag conveys an additional piece of information and since there can be any number of tags, the amount of data that can be conveyed is virtually limitless. There is no need to use a separate load file for native documents and image files and OCR data; they can all be clearly represented here.
<?xml version="1.0" encoding="utf-8" ?>
<Root MajorVersion="1" MinorVersion="1">
<Batch name="Sample Set">
<Documents>
<Document DocID="SAMPLE-0000001">
<Tags>
<Tag TagName="#StartPage" TagDataType="Text"
TagValue="SAMPLE-000001" />
<Tag TagName="#EndPage" TagDataType="Text"
TagValue="SAMPLE-000002" />
<Tag TagName="#ItemID" TagDataType="Integer"
TagValue="4075" />
<Tag TagName="#AttachmentCount" TagDataType="Integer"
TagValue="4" />
<Tag TagName="#From" TagDataType="Text"
TagValue="John Doerr <jdoerr@kpcb.com>" />
<Tag TagName="#To" TagDataType="Text"
TagValue="'larry_kanarek@mckinsey.com'
<larry.kanarek@mckinsey.com>; 'kenneth.lay@enron.com'
<kenneth.lay@enron.com>; 'blev@stern.nyu.edu'
<blev@stern.nyu.edu>; 'jbneff@wellmanage.com'
<jbneff@wellmanage.com>; 'hadlow@blackstone.com'
<hadlow@blackstone.com>; rick.sherlund@gs.com'
<rick.sherlund@gs.com>; 'jstiglitz@brookings.edu'
<jstiglitz@brookings.edu>; 'hal@sims.berkeley.edu'
<hal@sims.berkeley.edu>; corsog@sec.gov'
<corsog@sec.gov>" />
<Tag TagName="#CC" TagDataType="Text"
TagValue="John Doerr <jdoerr@kpcb.com>" />
<Tag TagName="#BCC" TagDataType="Text" TagValue="" />
<Tag TagName="#Subject" TagDataType="Text"
TagValue="Garten Commission" />
<Tag TagName="#RelativePath" TagDataType="Text"
TagValue="zl_lay-k_000.pstlay-kAll documents" />
<Tag TagName="#DateSent" TagDataType="DateTime"
TagValue="2000-11-20T03:38:00.0-05:00" />
<Tag TagName="#DocType" TagDataType="Text"
TagValue="Microsoft Outlook Message File" />
<Tag TagName="#Title" TagDataType="Text" TagValue="" />
<Tag TagName="#Author" TagDataType="Text" TagValue="" />
<Tag TagName="#DateCreated" TagDataType="DateTime"
TagValue="2010-06-19T18:21:00.0-04:00" />
<Tag TagName="#DateModified" TagDataType="DateTime"
TagValue="2000-1120T03:38:00.0-05:00" />
</Tags>
<Files>
<File FileType="Native">
<ExternalFile FilePath="\Sample Data_09_28_2011@
12-38-08PMSAMPLE0001IMG_0001" FileName="000000000
51205B956AA854CAC5F68870D78B0AB84492600.msg"
FileSize="51200" Hash="a2db1e5b29a2a2905f305e0fbb
56ad05" />
</File>
</Files>
</Document>
</Documents>
</Batch>
</Root>
Each tag name is repeated for each document, rather than having a list of fields at the top of the file, followed by a stream of delimited values. If a tag value is missing, it is immediately obvious in the XML file. There is no more need to determine which delimiter was used or if the delimiter was also used to separate values within a field (e.g., using commas for the delimiter and between email addresses).
Finally, EDRM XML is an open format, overseen by the EDRM XML group. The group represents a variety of vendors, lawyers and consultants that bring their ideas to better the format. Unlike proprietary formats, public input for the EDRM schema is not only welcome, it is actively encouraged. The format will be most useful with the input of the larger e-discovery community.
Summary
With issues of malformed data and system-specific idiosyncrasies removed, data sets can be imported much more quickly, and hence at much less cost. As companies and firms look for new ways to contain litigation costs, reducing the time it takes to import data sets can result in significant gains in efficiency. Requesting load files in EDRM XML format guarantees that you will receive data according to a common standard with no guesswork required, making the import faster and less costly.
Most major e-discovery systems already offer the ability to create EDRM XML load files instead of their default delimited formats, so the next time you receive a data set, request it in EDRM XML. Your litigation support team will thank you.
XML Benefits:
- Supports Unicode – Supports any language
- Self-describing – Doesn’t need another file to explain how to interpret additional information
- Flexible – Even as information gets more complex or data types change, XML is flexible enough to handle it
- Extensible – With no limit to the number of tags used, all metadata and other information can be conveyed in this single file
- Customizable – Create custom tags as needed