
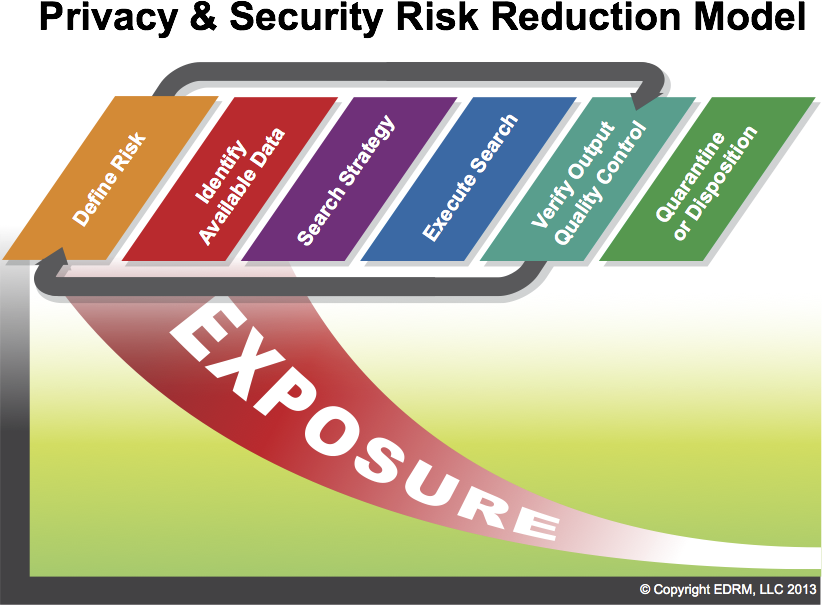
The Privacy & Security Risk Reduction Model is a process for reducing the volume of private, protected and risky data by using a series of steps applied in sequence. The model is used prior to producing or exporting data containing risky information such as privileged or proprietary information. The middle steps are cyclical and are repeated until the amount of private material is reduced to a desirable amount. The private data is finally quarantined in the final step before the remaining information is produced.
Define Risk
Risk is initially identified by an organization by stakeholders who can quantify the specific risks a particular class or type of data may pose. For example, risky data may include PII such as credit card numbers, attorney-client privileged communications or trade secrets.
Identify Available Data
Locations and types of risky data should be identified. Possible locations may include email repositories, backups, email and data archives, file shares, individual workstations and laptops, and portable storage devices. The quantity and type should also be specified.
Create Filters
Search methods and filters are created to ‘catch’ risky data. They may include keyword, data range, file type, subject line etc.
Run Filters
The filters are executed and the results evaluated for accuracy.
Verify Output
The data identified or captured by the filters is compared against the anticipated output. If the filters did not catch all the expected risky data, additional filters can be created or existing filters can be refined and the process run again. Additionally, the output from the filters may identify additional risky data or data sources in which case this new data should be subjected the risk reduction process.
Quarantine
After an acceptable amount of risky data has been identified through the process, it should be quarantined from the original data sets. This may be done through migration of non-risky data, or through extraction or deletion of the risky data from the original data set.