

[EDRM Editor’s Note: EDRM is proud to publish the advocacy and analysis of Tara S. Emory. The opinions and positions are those of Tara S. Emory. © Tara S. Emory 2025.]
This case study outlines a practical framework for evaluating Generative AI (“GenAI”) review for organizing documents in discovery using Relativity’s aiR for Review.1 We designed a testing and assessment protocol to identify when GenAI performed well, when it didn’t, and how to build effective hybrid workflows. These insights aim to guide legal teams considering GenAI for document organization and review.2
We began with a prioritized, traditional Technology-Assisted Review (“TAR”) workflow (also known as TAR 2.03) to identify key strategic documents, tagging for multiple issues. Later, we needed deeper insight into 7,100 documents tagged with one of those issues. That issue, as defined in the initial review, was broader than our new information need, so many tagged documents were not relevant to the more specific questions we now faced. In addition, the new information need was relatively urgent, so we needed to organize documents around these specific issues quickly and effectively.
Given the number and intricacy of those sub-issues identified by specialized senior attorneys, we anticipated that training and relying on other reviewers might lead to inconsistent results. These specialized, interrelated topics required high-level subject matter expertise. Quick development of a review team for such nuanced issues would be challenging. Therefore, we used Generative AI for document review to organize the documents into their respective sub-topics for efficient review by the senior attorneys. The process involved the senior attorneys creating and refining instructions (i.e., prompts) directing the AI system to follow when categorizing documents. This approach leveraged their specialized knowledge to train a single system to consistently sort documents based on their relevant sub-issues.
A. The Review Set: Over 7,000 Conceptually Similar Documents
First, our team conducted a TAR 2 review on incoming productions, to efficiently identify key strategic documents. The matter involved several different issues, which attorneys labelled with issue tags during review. Following that review, our team identified a need to quickly gain more detailed insights into an issue for which we had 7,100 tagged documents. Those tagged documents related to a single broad issue, and the new need involved a more nuanced understanding of complex legal and business sub-issues within that issue. The initial review tag was broader than the combined sub-issues, so many documents with this tag were not relevant to the new sub-issues we sought to identify.
This task, involving nine sub-topics comprising parts of the initial issue, presented unique challenges. The review would be time-consuming, given the volume of documents, and the number and nature of our nine intricate and interrelated issues. The complexity would require significant senior attorney (i.e., subject matter expert) input. Quick development of a review team for such nuanced issues would be challenging, and the time to analyze each document for the nine issues would be significant.
Therefore, we decided to use aiR’s GenAI-based Issues Review, which uses Generative Artificial Intelligence to review documents and predict responsiveness to multiple issues, based on user prompts. aiR scores documents on a 1-4 scale, where 1= not relevant; 2=borderline; 3=relevant; and 4=very relevant.
Unlike validation-driven TAR protocols often developed with defensibility concerns in mind,4 our objective was to develop a practical and efficient method to evaluate whether prompts were performing well enough for document organization, prioritization, and issue understanding. Formal validation across nine issues would have been too time-intensive and not aligned with our goals. The approach we developed allowed us to focus on practical evaluation, with useful feedback about our GenAI review results that guided our prompt iteration process, without the time and resources requirements of formal validation.
Unlike validation-driven TAR protocols often developed with defensibility concerns in mind, our objective was to develop a practical and efficient method to evaluate whether prompts were performing well enough for document organization, prioritization, and issue understanding.
Tara S. Emory.
B. Curating Strategic Test Sets
We developed a three-tier testing framework to assess the Gen-AI review performance. The foundation was Test Set 1, comprising 10 to 15 example documents per issue category, carefully selected by our subject matter expert to represent the full range of responsiveness. These documents served as our primary development set, where we iteratively refined and measured prompts across multiple rounds of testing.
First, a senior attorney (subject matter expert) identified about 10-15 key examples of each issue, which represented documents we most wanted to identify for that issue. Senior attorneys then tagged all selected example documents for all nine issues. We split this curated, labelled set in half, to create Test Set 1 and Test Set 2. We also randomly selected additional documents from the broader review set, which were similarly tagged for all nine issues by senior attorneys. These labelled sets served as “ground-truth” to compare against aiR predictions in each testing round.
This process allowed us to begin testing prompts on Test Set 1, and observe effects of efforts to refine prompts. Test Set 1 served as our primary set to develop prompts, iterating to improve aiR’s identification of these example documents for each topic. As a check against the risk of overfitting, we planned to use Test Set 2 (drawn from the same curated pool as Test Set 1) for further testing and iterating as needed.5 Some performance gap between these two sets would be expected, but a significant gap might suggest the prompts were overfitted to Test Set 1 and needed further refinement.
As a check against the risk of overfitting, we planned to use Test Set 2 (drawn from the same curated pool as Test Set 1) for further testing and iterating as needed. Some performance gap between these two sets would be expected, but a significant gap might suggest the prompts were overfitted to Test Set 1 and needed further refinement.
Tara S. Emory.
Finally, Test Set 3 provided a limited test of how the prompts would perform on the review set at large. Unlike the curated sets, this set contained documents with varying levels of importance for different issues. Because the initial issue was broader than the nine sub-issues, some sampled documents were not responsive to the more specific sub-issues. We reviewed until we had 20 examples that were responsive to at least one sub-issue. While this was a small sample, with uneven representation across issues, it would give us an idea of how the system would perform on responsive documents in the overall review set.
The review tiers each served to help us assess the questions:
Test Set 1 (Curated): Can we teach the system our concept?
Test Set 2 (Curated): Did the system learn the concept or memorize examples? If it only memorized examples, can we further iterate and improve it?
Test Set 3 (Representative): How will the system perform in practice?
This structured approach provided an efficient way to assess true performance and make informed decisions about further prompt refinement. While traditional TAR work often relies on recall and precision estimates based on random sampling, our targeted approach used small, curated datasets. We focused on raw document counts instead of statistical measures because these small, curated test sets cannot be readily extrapolated to estimate overall performance as is typical for recall and precision metrics. In addition, the raw counts provided clearer context for the practical significance of our results.
C. Prompt Iteration and Testing
Our iterative prompt refinement process focused on improving performance across all issues, a process that we iterated over the course of four prompts. Starting with Test Set 1, we tracked two key goals: 1) adjusting our prompt to find more of the relevant documents (i.e., increasing true positives); and 2) decreasing aiR’s incorrect predictions of responsiveness for documents that were not responsive (i.e., reducing false positives).
For each issue, in each round, we refined the prompts based on reviewing aiR’s predictions compared to our ground-truth tags. Senior attorneys provided specific feedback especially about documents that were misclassified, which we used to refine the prompts.Importantly, this iterative process also revealed how we could improve our aiR results through a hybrid approach, supplementing or narrowing results with other search methods, including metadata filters and targeted search terms.
Senior attorneys provided specific feedback especially about documents that were misclassified, which we used to refine the prompts.Importantly, this iterative process also revealed how we could improve our aiR results through a hybrid approach, supplementing or narrowing results with other search methods, including metadata filters and targeted search terms.
Tara S. Emory.
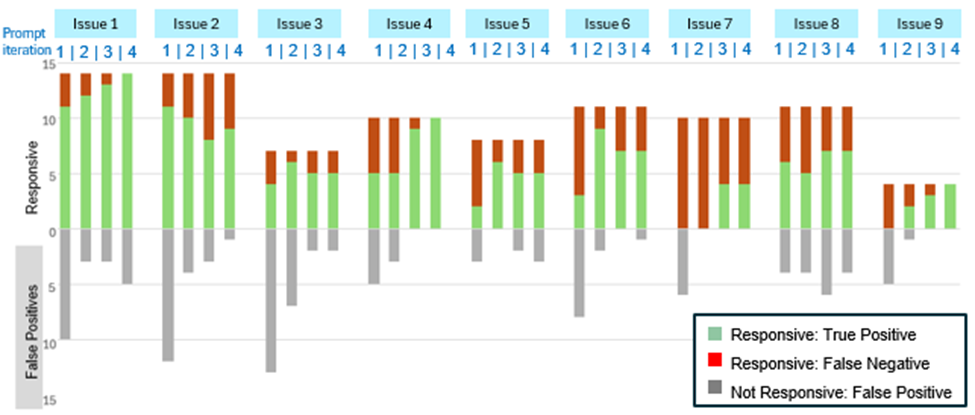
Figure 1 shows the results of aiR’s predictions through four rounds of prompting for each issue in Test Set 1. The combined green and red bars represent the total number of ground-truth responsive documents for each issue. Green bars are true positives that aiR correctly predicted as responsive in that round. The red portion of the bar are responsive documents that aiR predicted as not responsive, or false negatives. The gray bars below reflect the number of false positives, which are not-responsive documents that aiR predicted as responsive.
Through each round, we observed whether we successfully increased the green bar from prior rounds, while reducing the red and gray bars. Most issues showed meaningful improvement by increasing true positives and/or reducing false positives. Some issues (Issues 4 and 9) even achieved perfect performance for Test Set 1 by the fourth round of iteration, finding all relevant documents with zero false positives. The prompt refinements occasionally reduced performance; for Issues 5 and 6, Round 4 slightly increased false positives while not increasing true positives. However, we noted that these slight performance drops could be addressed through the supplemental metadata and keyword searches we had developed to use alongside the aiR results.
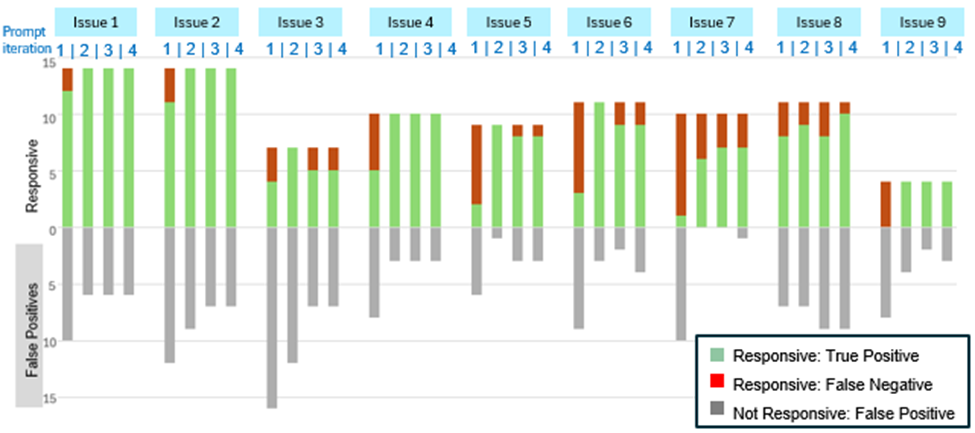
The visualization of prompt performance served as our team’s guide for strategic decisions about when our prompt engineering efforts were facing diminishing returns. We looked at results using a standard cutoff in aiR (documents scoring a 3 or 4 for Relevance), as shown above in Figure 1, and also when including borderline cutoff (scoring a 2 or higher), as shown in Figure 3 below. Across the issues, the performance generally had little room for improvement or plateaued by Round 4.
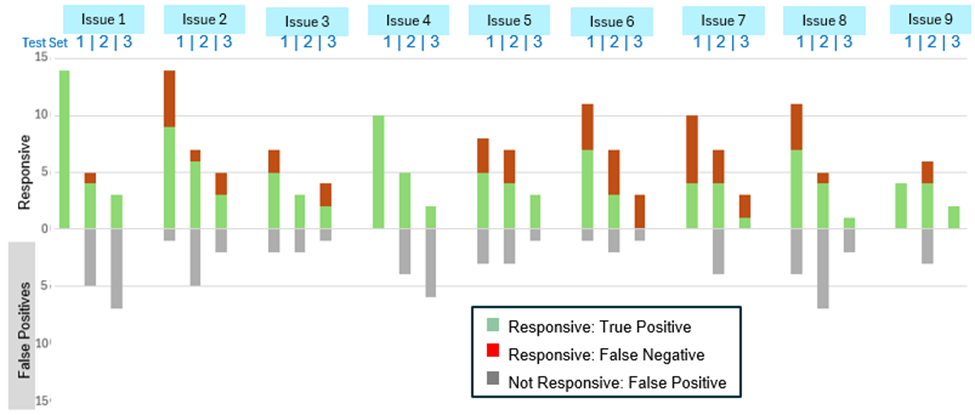
After four rounds of prompt iteration on Test Set 1, we tested the Round 4 prompts from Test Set 1 (“Refined Prompts”) on Test Set 2. While those prompts were not all the best-performing prompts for Test Set 1, we chose them because we believed they would work best in combination with the supplemental metadata and keyword searches we had developed. As expected, when applied to Test Set 2, performance was somewhat lower than Test Set 1, but the results were acceptable, especially given our planned hybrid search approach. We observed that most errors could be addressed by the supplemental searches, so Test Set 2 helped confirm those additional search methods would be effective.
Test Set 3 contained a random sample more representative of the broader review set, though these documents were also generally less critical than the documents in Tests 1 and 2. The Refined Prompts varied in their performance across issues in this set. Still, given our review goals, our understanding of where aiR performed well, and our insights into effective supplemental searches, we decided to proceed with applying the Refined Prompts to our overall review set, and focus on building hybrid searches that used aiR scores with other search techniques to organize and prioritize the documents.
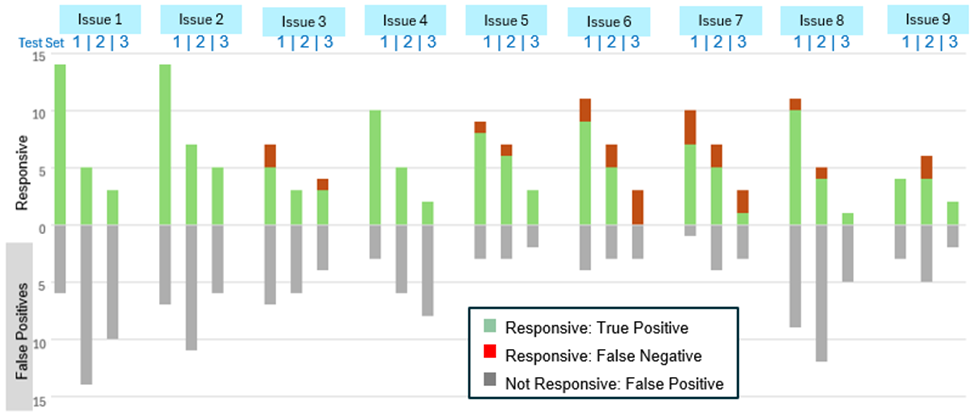
Figure 2 below reflects the performance of the Refined Prompts on curated Test Sets 1 and 2, and the random sample Set Test 3, using aiR’s standard cutoff score. We also considered the results using borderline cutoff scores, shown in Figure 4.
D. Results and Insights from Testing GenAI Review for Organization of Multiple Issues
Notably, we expected this document set to be challenging for aiR compared to typical document review sets. All of the review set documents had already been tagged as responsive to a broader issue, making them conceptually similar. The nine sub-issues we sought to identify were nuanced and interrelated, requiring fine distinctions within an already cohesive set. In all, of the 7,100 documents, aiR analyzed 6,622 without error. Of those, using the standard cutoff scores, it predicted 2,004 documents contained at least one issue, and 4,618 contained none. A sample of those documents predicted not responsive was 9% relevant, though those responsive documents in the sample were of low importance.
Our testing showed that GenAI review worked better for some issues than others. Issues requiring nuanced content analysis generally performed well. Issues with a rules-based component such as multiple criteria (e.g., mentioning a company plus discussing a topic), or dependent on date, had more limited performance. For example, Issue 8 was tied to specific date ranges and particular parties, and persistently produced higher false positive rates. As the nature of the documents became clearer through our reviews of iterative prompt results, we identified which issues would benefit more from metadata and keyword searches than additional prompt refinement. We supplemented Issue 5 with additional searches, while Issues 8 and 9 required both narrowing and supplementation.
Our testing showed that GenAI review worked better for some issues than others. Issues requiring nuanced content analysis generally performed well. Issues with a rules-based component such as multiple criteria (e.g., mentioning a company plus discussing a topic), or dependent on date, had more limited performance.
Tara S. Emory.
Developing and refining these prompts required significant upfront investment from senior attorneys. aiR then effectively scaled their expertise across the document set. The iterative testing process guided our prompt refinement and determination of appropriate score cutoffs for each issue.
Based on the results, we also determined that we would use aiR’s standard relevance cutoff score of 3 for most issues. However, for Issues 2 and 7, we included the borderline documents with a score of 2. These specific issues were highly important, and testing showed this captured significantly more responsive documents with reasonable false positive increases, justifying the tradeoff.
This hybrid search strategy emerged organically from the testing insights. Different legal and factual issues have different characteristics that align better with different search methods. GenAI review was valuable in achieving our goals as one search tool among others, rather than a replacement for them.
We then used these strategies to prioritize human review of key documents: first, high-scoring aiR results (score of 4); then standard responsive scores (score of 3); and then, for certain issues, borderline documents (score of 2). For some issues, we applied filters to narrow results across all score levels. We also used supplemental searches to identify additional relevant documents, treating these as standard responsive (score of 3). This structure allowed us to strategically prioritize human review of key documents.
This matter demonstrated three key lessons for GenAI review in legal workflows. First, the upfront investment in prompt development and testing can be substantial (especially for multiple issue prompts), but can enable senior attorneys to scale their expertise for review involving complex, nuanced issues. Second, systematic monitoring throughout the process can inform both prompt refinement and strategic decisions about score cutoffs. Third, GenAI review is another search tool that can be combined effectively with traditional search methods. Strategic search design involves understanding each tool’s capabilities, and the different legal and factual characteristics of different search needs.
Results with Borderline Score Cutoff:
Notes
- See Relativity aiR for Review, https://www.relativity.com/data-solutions/air/. ↩︎
- This case study describes work performed on incoming document productions from other parties and does not involve client data. For more information about application of GenAI to document review workflows, see Omrani, et. al., Beyond the Bar: Generative AI as a Transformative Component in Legal Document Review, 2024 lE International Conference on Big Data (BigData), Washington, DC, USA, 2024, pp. 4779-4788, doi: 10.1109/BigData62323.2024.10826089. ↩︎
- TAR 2 workflow involves developing a machine-learning model, based on human-reviewed documents, to predict which unreviewed documents are most likely responsive, and prioritizing those documents for human review. The ongoing human review then continuously trains the model. ↩︎
- See T. Emory, J. Pickens, W. Lewis, TAR 1 Reference Model: An Established Framework Unifying Traditional and GenAI Approaches to Technology-Assisted Review (2024). In this case study, we adapted the TAR 1 Reference Model’s systematic testing and iteration principles, given that this project did not require formal validation. ↩︎
- Overfitting occurs when a system learns to perform well on the specific examples it was trained on but fails to generalize to new, similar documents. In this case, this would mean we might develop prompts that worked perfectly on Test Set 1 but performed poorly on other documents because the prompts had essentially “memorized” the training examples rather than learning important, broader concepts. ↩︎
Assisted by GAI and LLM Technologies per EDRM GAI and LLM Policy.
