
[Editor’s Note: EDRM is grateful to Matthew Golab and Susan Bennett of EDRM Trusted Partner, InfoGovANZ, for permission to republish this article, first published on April 6, 2023.]
2023 appears to be well and truly the year of AI. Ever since the release and world-wide attention of ChatGPT by OpenAI in late in 2022, followed recently with the release of GPT-4, it seems there is a new release or a new revelation on a daily basis about the way in which these Generative AI tools appear to be able to do with ease, tasks that have previously been very labour intensive and manual. Regardless of how far we will be able to utilise these tools and integrate them into the corporate workplace, clearly the advent of AI systems being able to generate text with little or no effort or cost, is the precipice of significant change.
The purpose of this article is to provide some insights into these tools, and some considerations in how they could be used, and some tips for crafting prompts and using LLMs.
The GPT acronym means Generative Pre-trained Transformer. A key aspect of GPT is that you are entering your instructions/commands in your normal language via a prompt or dialogue box. The LLM acronym means Large Language Model.
Background
I have worked in information science in the legal sector since the late 1990s and have been working in eDiscovery in law firms since 2000. When AI was introduced into eDiscovery about a decade ago (in the form of machine learning; document clustering; and categorisation), I rapidly became an avid AI enthusiast. We use these technologies extensively in our day-to-day eDiscovery work, and without the assistance of these technologies it would be quite difficult for us to be able to manage the scale of data that we handle in our typical large scale document reviews.
These new Generative AI systems are very different to the AI technologies that we’ve been using in law firms for the past decade, and potentially could impact many aspects of work. Broadly speaking, the use of AI within a law firm has been limited to discrete tasks in the form of large-scale document review or used in administrative functions such as in finance with analytics for the management of revenue as well as forecasting for clients.
A major difference though is that with these existing systems, they have largely relied upon a lot of human effort in the form of training and supervision, or rules or carefully curated data sets/frameworks. Whereas with Generative AI, it appears that the amount of initial effort is quite low, and the output can at times be amazing. Of course, for high precision work, the output can also be very misleading, and for example in legal research the output can be initially quite convincing while it blithely fabricates caselaw or legislation that simply does not exist – this behaviour is commonly called the hallucinations from the Generative AI systems. This poses considerable risk in that if you do not have the depth of knowledge or familiarity with the subject matter then it is going to be very difficult for you to be able to verify the results and to be able to trust them.
Nevertheless, it is an incredibly exciting time to be working in this field, and to watch the rapid pace of technological development, while also working out novel ways in which we can harness these technologies to augment human efforts – and of course in a perfect world to remove a level of manual effort in low level tasks altogether.
The Recent Past – Transformers and LLMs
Very quickly after the release of the landmark Transformers paper Attention is all you need by Google in 2017, increasingly larger and more complex large language models (LLMs) have been released, as you can see from the graph below the incredible scale of these models. Note that GPT-4 by OpenAI is not included as OpenAI are no longer publicly sharing details on the scale of parameters or the training data used for this model. Prior to GPT-4 being released in late March 2023, there was speculation that GPT-4 would be significantly larger than the 175 billion parameters in GPT-3, however until OpenAI are more forthcoming on the details on GPT-4 no-one knows.
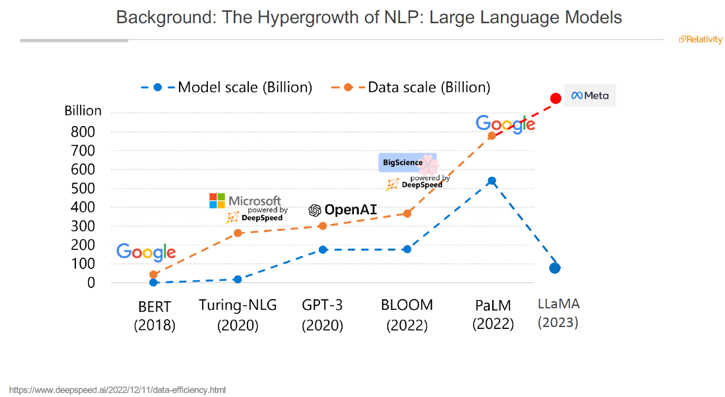
Image credit Dr Cao (Danica) Xiao, VP Research – Machine Learning Relativity from the presentation “AI Masterclass: What you need to know as a Legal Professional”, 9 March 2023, Relativity Spotlight ANZ, which I had the pleasure of co-presenting.
Although I have been focusing on the textual aspect of Generative AI, there has of course been a lot of success with other modes of Generative AI, for example with the releases in mid-2022 of image generation DALL-E by OpenAI and followed quickly by the open-source Stable Diffusion by Stability ai, and Midjourney. For example, I used Stable Diffusion to generate the image for this article using a variation of the prompt:
fullpage design, information governance ANZ, law, stoic justice, knowledge, generative AI, by james gleeson and a starburst, 35mm, red tones, panoramic, futuristic, 4k, french revolution
Stephen Wolfram has written an excellent article explaining how ChatGPT (and Transformers) work What Is ChatGPT Doing … and Why Does It Work?. Wolfram Alpha powers Siri on Apple mobile devices.
Current Playing Field
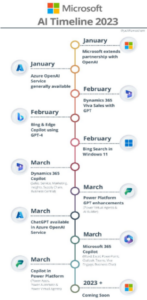
- Microsoft and OpenAI/GPT-4
In addition to the significant attention with ChatGPT by OpenAI, there is also the partnership with Microsoft that started in 2019 with the announcement that Microsoft had invested USD$1 billion into OpenAI. In late January 2023, Microsoft announced a multi-year USD$10 billion investment into OpenAI, followed in February with the integration of GPT-4 into the Microsoft search engine Bing and web browser Edge, and in late March 2023 Microsoft announced Microsoft 365 Copilot where GPT-4 will be integrated throughout a lot of the Microsoft eco-system.
Credit for the graphic to Jack Rowbotham who is a Microsoft Product Marketing Manager and posted the graphic on his LinkedIn
Predating all of the attention being paid to ChatGPT, OpenAI released in mid-2021 GitHub Copilot and in late March 2023 GitHub Copilot X. These are natural language tools for software development, and GitHub Copilot X is marketed as Your AI pair programmer is levelling up with chat and terminal interfaces, support for pull requests, and early adoption of OpenAI’s GPT-4, GitHub Copilot X is our vision for the future of AI-powered software development. Integrated into every part of your workflow.
Microsoft acquired GitHub in late 2018, and as of early 2023, GitHub reported that it was used by over 100 million developers, and more than 372 million code repositories including at least 28 million public code repositories. It is the largest source code host as of late 2021. GitHub Copilot was trained on these code repositories, and presumably as was GitHub Copilot X.
As mentioned in the Transformers section, Google have released many significant papers and technologies, and continue to do cutting edge research. They provided an interesting overview of 2022 and beyond Google Research, 2022 & beyond: Language, vision and generative models.
Along with the release of Bard, Google also released a revision of their AI platform called LaMDA , which is based on their breakthrough in building an adaptive conversation language model. Unlike ChatGPT, which was trained on massive web data, LaMDA was trained using advanced human dialogue data, enabling it to differentiate the nuances of human language. LaMDA is equipped with multimodal input and output channels, including voice and text-based interfaces, and is designed to support various tools for customization. While ChatGPT can be fine-tuned to support local applications, LaMDA is focused on industry applications, such as healthcare and finance.
Unfortunately, the launch of Google’s was a fairly lack lustre launch when it got a key fact wrong, and from various side by side comparisons it appears that Bard lags a fair way behind its competitor, Chat-GPT. The MIT Technology Review wrote a good article on Bard titled, ‘Google just launched Bard, its answer to ChatGPT – and it wants you to make it better.’ At the time of writing this article, Bard is not yet accessible in Australia.
- Meta
Meta and their FAIR team are quite prolific in research papers and in late February 2023 released the cutting-edge LLaMA LLM LLaMA: Open and Efficient Foundation Language Models. FAIR emphasise that LLaMA has been trained using publicly available datasets and that it is very efficient both in training and the energy used to train it, and able to be trained on consumer grade hardware (as opposed to supercomputers), as well as outperforming GPT-3 by 10x smaller. LLaMA was released as open source to the research community.
Not long after the release of LLaMA, the models and their accompanying weights (a 240GB download) were leaked, and there have been some innovative adaptations for example being able to run the model on a MacBook Pro. It will be fascinating to see what open-source competitors to Chat-GPT and GPT-4 are built upon the leaked LLaMA models.
- Notable open-source models
It may seem like I am favouring OpenAI in this article, there of course have been numerous open-source models released following on from the release of OpenAI models, as well as significant releases by Google and Meta, as well as other big-tech companies and research institutions, however I’m simply referring to the OpenAI models as they are the most well-known. For those who are interested, this Wikipedia article on OpenAI is worthwhile reading.
The models chosen below are just a few notable examples, as apparently in the last week of March, there were 200 new AI tools released. There is a very useful tracking website called There’s An AI For That – Find AI Tools Using AI.
Bloom (BigScience Large Open-science Open-access Multilingual Language Model) was released in mid-2022 and was a collaborative effort involving 1,000 researchers from 70+ countries and 250+ institutions. Interestingly, they share insights on the final training run which ran for 117 days on a supercomputer costing circa €3 million.
GPT-J was released in mid-2021 and is an open-source competitor to GPT-3
Stanford Alpaca by Stanford CRFM – this is based upon the Meta LLaMA model; however, the public website was taken down on 21 March 2023 due to hallucination issues. What is amazing about Alpaca is that it was trained for about USD$600. Consider that Bloom cost €3 million to train.
- AI Services
Hugging Face Hugging Face is a large open-source AI community that was launched in 2016, most commonly known for its easy-to-use, deep learning python libraries. There is an extensive library of 100+ transformers.
Hugging Face in Amazon Web Services (AWS) Hugging Face transformer models can also be hosted within AWS, which means you can use these as services within your organisation e.g., without your own private cloud hosted in AWS
During 2023 we should see significant advances in the release of multi-modal generative AI, meaning that in addition to image and text generation, these systems will also be able to generate audio and video.
Impact of AI on legal practice
The following are a selection of articles from different spheres of legal technology setting out the views of the authors on the use of GPT/LLMs applicable to different areas of law and legal practise. There has been an explosion of interest and content with the rapid releases and enhancements to Chat-GPT and GPT-4 and these selected articles below are designed just to give a few different perspectives.
- Professor Dan Katz, Michael Bommarito & Ors released two landmark studies – the first was in late December 2022, following testing of GPT3.5 against the multistate section (MBE) of the US Bar Exam GPT takes the Bar Exam, and the second was in March 2023, following testing of GPT-4 against the entire Uniform Bar Exam (UBE) GPT-4 Passes the Bar Exam.
In the space of 3 months, the performance of GPT3.5 was impressive, but overall inferior to human, and then with GPT-4, the results were simply amazing. As they state in their conclusion:
Less than three months ago, we predicted that passage of the MBE would likely occur in the next 0-18 months,” and in this paper, we provide preliminary evidence of GPT-4’s zero-shot passage of the entire UBE. The exam, which includes both multiple-choice and open-ended tasks testing theoretical knowledge and practical lawyering, has long been viewed as an insurmountable summit for even domain-specific models. This assumption no longer holds; large language models can meet the standard applied to human lawyers in nearly all jurisdictions in the United States by tackling complex tasks requiring deep legal knowledge, reading comprehension, and writing ability.
Most notably, the results documented in this paper reflect only zero-shot model behaviour. While many real tasks in industry and society broadly require more knowledge and ability than tested on the Exam itself, there is significant opportunity to advance the performance of large language models through external queries, scratchpads, chain-of-thought prompting (CoT), or one of the many other techniques that emerges weekly. Our findings only highlight the floor, not the ceiling, of future application.
As the demand for better, faster, and more affordable legal services is only increasing in society, the need for supporting technology is becoming more acute. Further research on translating the capabilities of LLMs like GPT-4 into real public and private applications will be critical for safe and efficient use. GPT-4, like prior models, may still hallucinate sources, incorrectly interpret facts, or fail to follow ethical requirements; for the foreseeable future, application should feature “human-in-the-loop” workflows or similar safeguards. However, it appears that the long-awaited legal force multiplier is finally here.
It is well worthwhile reading their GPT-4 Passes the Bar Exam paper in full.
- Contract analysis – Noah Waisberg and the Zuva team in How is GPT-4 at Contract Analysis? state:
GPT-4 has generally really impressed us. It appears able to do a lot very well. That said, we are unconvinced that it yet offers predictable accuracy on contract analysis tasks. (And we have not yet really pushed it, for example on poor quality scans and less standard wordings, though perhaps it would do well on these.) If you use Generative AI to help you find contracts with a change of control clause, it will identify change of control clauses in contracts. If, however, you need it to find all (or nearly all) change of control clauses over a group of contracts, we wouldn’t yet count on it. Still, this technology is improving, and our view may change as we test further iterations. Also, as we’ll discuss in a further installment, we think LLMs offer significant benefits today when combined with other machine learning contract analysis technologies. Exciting!
- eDiscovery – John Tredennick and William Webber Will ChatGPT Replace Ediscovery Review Teams?
We started this article with the question, “Could GPT replace human reviewers?”. The answer is: “potentially yes, with appropriate guidance”. On a substantial proportion of topics, GPT achieved human-level quality of review, at a fraction of the cost and time. Where it fell short, there is good reason to believe that results could be improved by more detailed topic descriptions and better-crafted prompts. And, we are confident that other AI algorithms, including those used for TAR, can be integrated to quickly and efficiently improve the results. To be sure, in some cases GPT hallucinated specious reasons for finding irrelevant documents relevant. When it does, there is a risk of it filling up the “relevant” pile with its idle fancies. All of these issues require further exploration in the lab and likely will require expert monitoring in the field, at least for the time being.
Why does this matter? Because the cost of civil litigation is too high and ediscovery makes up a large portion of those costs. If we can use artificial intelligence programs to reduce a major component of ediscovery costs, we can help make access to justice more affordable. After all, ediscovery, while important, is not the primary purpose for the litigation process. It is only a sideshow for the main event.
- Ways LLM can help lawyers – Ralph Losey Ten Ways LLM Models Such as ChatGPT Can Be Used To Assist Lawyers
- Streamlined Legal Research
- Efficient Document Drafting
- Enhanced Legal Analysis
- Due Diligence Reinvented
- Revolutionizing Contract Review
- E-Discovery Reimagined
- Case Management Mastery
- Alternative Dispute Resolution (ADR) Enhanced
- AI-Driven Legal Education and Training
- Client Communication Elevated
- SALI Harnesses Most Advanced GPT Models to Help Legal Industry ‘Speak the Same Data Language’ , Standards for the Legal Industry (SALI) Alliance, the non-profit group behind the creation of universal tagging to bring standardization to the way the legal industry references and communicates about matter types and services, announced this week a new AI-powered tool to quickly and accurately perform SALI tagging. Specifically, the new offering will have access to both GPT-3.5-Turbo and GPT-4 AI models to help eliminate the enormous variation in the ways lawyers describe tasks, matters, practice areas and more.
SALI is making their new AI-powered tagging available to users in three ways.
The first is through the web. SALI users can input text, the SALI engine will run a fuzzy match to identify language that corresponds to SALI tags. If there’s no match, they run something called Jaccard similarity. If there’s still no match, they’ll then run the text through the GPT-4 to identify appropriate tags. The second means of access is through APIs.
A third way is to download all the code that underlies the SALI API via GitHub and run it behind your organization’s walls, free of charge.
- In Bill Gates’ latest blog on the Gates Notes newsletter The Age of AI has begun, he outlines his views on AI including:
- personal AI agents:
- improvements in healthcare and medicine; and
- education.
- Rodney Brooks – What Will Transformers Transform?, this is a very thoughtful and pragmatic article, and is well worthwhile reading. He is one of the early pioneers of robotics and AI. He ends the article with the predictions:
Here I make some predictions for things that will happen with GPT types of systems, and sometimes coupled with stable diffusion image generation. These predictions cover the time between now and 2030. Some of them are about direct uses of GPTs and some are about the second and third order effects they will drive.
- After years of Wikipedia being derided as not a referable authority, and not being allowed to be used as a source in serious work, it will become the standard rock solid authority on just about everything. This is because it has built a human powered approach to verifying factual knowledge in a world of high frequency human generated noise.
- Any GPT-based application that can be relied upon will have to be super-boxed in, and so the power of its “creativity” will be severely limited.
- GPT-based applications that are used for creativity will continue to have horrible edge cases that sometimes rear their ugly heads when least expected, and furthermore, the things that they create will often arguably be stealing the artistic output of unacknowledged humans.
- There will be no viable robotics applications that harness the serious power of GPTs in any meaningful way.
- It is going to be easier to build from scratch software stacks that look a lot like existing software stacks.
- There will be much confusion about whether code infringes on copyright, and so there will be a growth in companies that are used to certify that no unlicensed code appears in software builds.
- There will be surprising things built with GPTs, both good and bad, that no-one has yet talked about, or even conceived.
- There will be incredible amounts of misinformation deliberately created in campaigns for all sorts of arenas from political to criminal, and reliance on expertise will become more discredited, since the noise will drown out any signal at all.
- There will be new categories of pornography.
- AI Tools for Lawyers: A Practical Guide this draft paper is full of very interesting tips for lawyers and is worthwhile reading in full, as it has a significant focus on ways to think about crafting prompts for GPT engines, as well as considerations regarding the ethical use of GPT engines and the obligations for lawyers.
- Attention is not all you need: the complicated case of ethically using large language models in healthcare and medicine by Stefan Harrer, The Lancet, Vol 90, April 2023 – although this article is written for healthcare and medicine, almost all of this is applicable for law
- Training – it is worthwhile considering further education in regards to how to use these models, and to gain greater technical understanding of how they work (one way is to follow the numerous hyperlinks in this article), so that you are growing your awareness of how to avoid common pitfalls when using these tools – for example they aren’t search engines.
Considerations and Risks
All is not rosy though, as there are considerable concerns regarding these LLMs including:
- Hallucinations – out of the box, the output from these systems can be very persuasive that it is correct, and there are numerous public examples of this behaviour, which I suspect led OpenAI to limit the correspondence with ChatGPT to a maximum of 5 rounds. There is a comprehensive Wikipedia page on AI Hallucinations;
- Training data and bias – little is known about the training data of these models or of the efforts to remove bias, however there is a fair bit of public scepticism, particularly with OpenAI no longer being open regarding the details with GPT-4;
- Training data and lawsuits – in January 2023 Getty Images sued Stability AI (the creators of Stable Diffusion) claiming infringement of intellectual property rights and that Stability AI unlawfully copied and processed millions of images protected by copyright and the associated metadata, as well as Stability AI is being sued by a group of artists in a class action matter, with the plaintiffs seeking $1B in damages on the basis that the defendant’s AI technology had been trained to recreate images reminiscent (but not exact copies) of prior art by scraping the internet of more than five billion images;
- LLMs and memory – LLMs are also criticised as being shallow and not being able to learn or remember;
- Training on your data – currently most of these systems are being used either by you uploading content directly, or by your system transferring data by API, it isn’t currently clear what happens to your data once it has been transferred and whether your data is used for training in the future, I’d strongly recommend to only use data that is in the public realm in these systems;
- Training of model – it takes considerable computing power (Microsoft built a Supercomputer for OpenAI to train GPT-4) to build these models, and Chat-GPT and GPT-4 are generally limited to knowledge up to 2021;
- Shallowness – that the system is generating text based upon its statistical prediction of the next word, however it does not actually comprehend language.
It is worthwhile reading the OpenAI paper GPT-4 System Card as it explains some of the safety processes that OpenAI adopted in preparing GPT-4 for deployment. The following is from their conclusion and next steps section:
Additionally, there are a few key steps that we are taking and encourage other developers of language models to adopt:
- Adopt layers of mitigations throughout the model system: As models get more powerful and are adopted more widely, it is critical to have multiple levels of defense, including changes to the model itself, oversight and monitoring of model usage, and product design for safe usage.
- Build evaluations, mitigations, and approach deployment with real-world usage in mind: Context of use such as who the users are, what the specific use case is, where the model is being deployed, etc., is critical to mitigating actual harms associated with language models and ensuring their deployment is as beneficial as possible. It’s particularly important to account for real-world vulnerabilities, humans’ roles in the deployment context, and adversarial attempts. We especially encourage the development of high-quality evaluations and testing of model mitigations on datasets in multiple languages.
- Ensure that safety assessments cover emergent risks: As models get more capable, we should be prepared for emergent capabilities and complex interactions to pose novel safety issues. It’s important to develop evaluation methods that can be targeted at advanced capabilities that could be particularly dangerous if they emerged in future models, while also being open-ended enough to detect unforeseen risks.
- Be cognizant of, and plan for, capability jumps “in the wild”: Methods like fine-tuning and chain-of-thought prompting could lead to capability jumps in the same base model. This should be accounted for explicitly in internal safety testing procedures and evaluations. And a precautionary principle should be applied: above a safety critical threshold, assurance of sufficient safety is required.
The increase in capabilities and adoption of these models have made the challenges and consequences of those challenges outlined in this card imminent. As a result, we especially encourage more research into:
- Economic impacts of AI and increased automation, and the structures needed to make the transition for society smoother
- Structures that allow broader public participation into decisions regarding what is considered the “optimal” behaviour for these models
- Evaluations for risky emergent behaviours, such as situational awareness, persuasion, and long-horizon planning
- Interpretability, explainability, and calibration, to address the current nature of “black-box” AI models. We also encourage research into effective means of promoting AI literacy to aid appropriate scrutiny to model outputs.
Ownership of content
Another major consideration in the use of these online systems/services is the ownership of any content. For example, the Bing Chat Terms of Usestate (highlighting for emphasis):
- Ownership of Content. Microsoft does not claim ownership of Captions, Prompts, Creations, or any other content you provide, post, input, or submit to, or receive from, the Online Services (including feedback and suggestions). However, by using the Online Services, posting, uploading, inputting, providing or submitting content you are granting Microsoft, its affiliated companies and third party partners permission to use the Captions, Prompts, Creations, and related content in connection with the operation of its businesses (including, without limitation, all Microsoft Services), including, without limitation, the license rights to: copy, distribute, transmit, publicly display, publicly perform, reproduce, edit, translate and reformat the Captions, Prompts, Creations, and other content you provide; and the right to sublicense such rights to any supplier of the Online Services.
No compensation will be paid with respect to the use of your content, as provided herein. Microsoft is under no obligation to post or use any content you may provide, and Microsoft may remove any content at any time in its sole discretion.
You warrant and represent that you own or otherwise control all of the rights to your content as described in these Terms of Use including, without limitation, all the rights necessary for you to provide, post, upload, input or submit the content.
Risks with your data
On 20 March 2023, there was an outage of ChatGPT, and on 24 March OpenAI published a blog post March 20 ChatGPT outage: Here’s what happenedwhere they clarified that personal data for subscribers of ChatGPT Plus was visible to other subscribers as follows:
- first and last name, email address, payment address, the last four digits (only) of a credit card number, and credit card expiration date; and
- a conversation history was shared with a different user.
It is an unfortunate reality that in 2023, our personal data may have been leaked.
Prompt tips using LLMs
For GPT-4 suggest prompts by typing the italicised text below and entering a description of the subject matter:
You are GPT-4, OpenAI’s advanced language model. Today, your job is to generate prompts for GPT-4. Can you generate the best prompts on ways to[insert description of what you want]
You can then use the output as a framework for you to explore different ways of generating prompts.
Other tips – these excellent tips are from Kareem Carr (with some editing)
- Never ask an LLM for information you can’t validate yourself, or to do a task that you can’t verify has been completed correctly.
- The one exception is when it’s not a crucial task. For instance, asking an LLM for apartment decorating ideas is fine.
- ❌ Bad: “Using literature review best practices, summarize the research on breast cancer over the last ten years.”
This is a bad request because you can’t directly check if it’s summarized the literature correctly. - ✅ Better: “Give me a list of the top review articles on breast cancer research from the last 10 years.”
This is better because you can verify that the sources exist and vet them yourself and of course, they are authored by human experts.
- Set the context:
- Tell the LLM explicitly what information it should be using
- Use terminology and notation that biases the LLM towards the right context
- If you have thoughts about how to approach a request tell the LLM to use that approach.
- ❌ “Solve this inequality”
- ✅ “Solve this inequality using Cauchy-Schwarz theorem followed by an application of completing the square.”
These models are a lot more linguistically sophisticated than you might imagine. Even extremely vague guidelines can helpful.
- Be specific – this isn’t google. You don’t have to worry about whether there’s a website that discusses your exact problem.
- ❌ “How do I solve a simultaneous equation involving quadratic terms?”
- ✅ “Solve x=(1/2)(a+b) and y= (1/3) (a^2+ab+b^2) for a and b”
- Define your output format and take advantage of the flexibility of LLMs to format the output in the way that’s best for you such as:
- Code
- Mathematical formulas
- An essay
- A tutorial
- Bullet points
You can even ask for code that generates:
- Tables
- Plots
- Diagrams
Once you have the output of an LLM, that is only the beginning. You then need to validate the response. This includes:
- Finding inconsistencies
- Googling terminology in the response to get supporting sources
- Where possible, generating code to test the claims yourself.
- LLMs often make weird mistakes that are inconsistent with their seeming level of expertise. For instance, an LLM might mention an extremely advanced mathematical concept yet fumble over simple algebra. This is why you need to check everything.
- Use the errors to generate feedback:
- If you see an error or inconsistency in the response, ask the LLM to explain it
- If the LLM generates code with bugs, cut and paste the error messages into the LLM window and ask for a fix
Ask more than once, LLMs are random. Sometimes simply starting a new window and asking your question again can give you a better answer.
- Use more than one LLM. I currently use Bing AI, GPT-4, GPT-3.5, and Bard AI depending on my needs. They have different strengths and weaknesses.
- It’s good to ask GPT-4 and Bard AI the same maths questions to get different perspectives. Bing AI is good for web searches. GPT-4 is significantly smarter than GPT-3.5 (like a student at the 90th percentile vs the 10th percentile) but harder to access (for now).
- References are an especially weak point for LLMs. Sometimes, the references an LLM gives you exist and sometimes they don’t. The fake references aren’t completely useless. In my experience, the words in the fake references are usually related to real terms and researchers in the relevant field. So, googling these terms can often get you closer to the information you’re looking for. Additionally, Bing AI is designed to find web references so it’s also a good option when hunting sources.
- Productivity There are a lot of unrealistic claims that LLMs can make you 10x or even 100x more productive. In my experience, that kind of speedup only makes sense in cases where none of the work is being double-checked which would be irresponsible for me as an academic. However, specific areas where LLMs have been a big improvement on my academic workflow are:
- Prototyping ideas
- Identifying dead-end ideas
- Speeding up tedious data reformatting tasks
- Learning new programming languages, packages and concepts
- Google searches
I spend less time stuck on what to do next. LLMs help me advance even vague or partial ideas into full solutions. LLMs also reduce the time I spend on distracting and tedious side tasks unrelated to my main goal. I find that I enter a flow state and I’m able to just keep going. This means I can work for longer periods without burnout. One final word of advice: Be careful not to get sucked into side projects. The sudden increase in productivity from these tools can be intoxicating and can lead to a loss of focus.
This seems like a good time to remember Arthur C. Clarke’s Third Law:
“Any sufficiently advanced technology is indistinguishable from magic”
Author: Matthew Golab, Director Legal Informatics & R+D at Gilbert + Tobin, InfoGovANZ International Council, and EDRM Global Advisory Council.