

By John Tredennick and William Webber[1]
[Editor’s Note: EDRM is proud to amplify the earned media of our Trusted Partners. This article was originally published by the American Lawyer Media in Law.com on February 21, 2023 and is circulated with permission.]
In a recent issue of Law.com, we asked the question “What will Ediscovery Lawyers do after ChatGPT? While the title was facetious, we, like so many others, were interested in how ChatGPT, this amazing new algorithm from OpenAI, might impact legal professionals.
ChatGPT is a new AI tool capable of answering complex questions and generating a conversational response. It can intelligently talk about almost any field–science, literature, humanities, history, even politics (at least up to September of 2021). It can also draft convincing arguments, write term papers, tell jokes and even speak “Pirate.” And, it reportedly passed a number of professional exams including one for medical licensing, an MBA test and even the legal bar.
Not surprisingly, we wondered how this new software might help improve ediscovery, a process involving the search and review of documents for use in legal proceedings and investigations. Over the past few years, the ediscovery market has grown to over $14 billion. Human document review makes up at least 60% of those costs, with over $8 billion being spent on analyzing and identifying relevant documents. Put simply, a lot of money is spent on human review that may or may not contribute to the quality of justice eventually obtained.
Knowing something about the strengths (and weaknesses) of ChatGPT, and its underlying analytics engine GPT-3.5, we felt compelled to ask the question: “Could GPT help reduce review costs?” As our research progressed, we got bolder and found ourselves asking: “Could GPT actually replace human reviewers?” If the answer were “Yes,” or even “Yes with some help from humans,” we might be able to shave billions of dollars off ediscovery review costs. That would be a good thing for all litigants and help make access to justice more affordable.
The Goal: More Efficient Review
Current ediscovery review practices vary, but most involve some combination of keyword search to narrow down the document population and human review for relevance. In recent years, many of us added AI machine learning to the process under the guise of Predictive Coding or Technology Assisted Review (collectively “TAR”).
TAR is a process whereby humans train a machine learning algorithm to recognize relevant documents. The algorithm then orders the documents for review, most-likely-relevant documents first. It has been an important ediscovery breakthrough, reducing the number of documents requiring human review by substantial percentages. Our question was: “Can we improve on TAR through cyber reviewers?”
Review Standards
All or nearly all courts approve TAR processes, recognizing that it would be impossible or at least cost prohibitive to try and review every collected document. Even in the old days of paper discovery, the true goal wasn’t to locate 100% of all relevant documents (to achieve, that is, 100% recall). Today, a producing litigant can be comfortable certifying recall in the range of 75 to 80%, arguing that finding additional marginally relevant documents would involve disproportionate expense with little gain in relevant information..
A costly issue for many reviews lies in the large amount of irrelevant material returned when using keyword search and even, in some cases, TAR. In our experience, keyword searches bring back a lot of irrelevant documents, often as many as ten to one, which burdens review teams and jacks up review costs. A good TAR algorithm can increase precision (the proportion of documents in the review stream that are relevant) upwards of 60% but that still leaves a lot of documents to be reviewed. Either way, the inefficiencies of modern review add substantially to most litigation budgets
Review Time
The problem with review goes at least one step further. Relevance reviews take time and human reviewers make mistakes. Both combine to make the review process less effective and certainly more expensive.
On average, human reviewers can process about 60 documents an hour (about a document a minute). Following that metric, it would take a team of 10 almost a year to get through a million documents. Even if you increase team size, the work is slow and arduous, almost mind-numbing according to some reports. Any thought that human reviewers can stay focused after hours of looking at boring documents is fanciful. Mistakes are frequent, and can be difficult to detect or remedy.
Could GPT improve the review process, or at least make it less costly? In asking this question we are not looking for perfection! Humans are far from perfect and we shouldn’t expect more from an algorithm, at least not for this type of work. Rather, the question is this: “Could GPT achieve a similar level of recall, say 75%, more quickly and at a lower cost than human review – even than human review assisted by TAR?” If it could, we would have something to talk about.
Our Research: Putting GPT to the Test in a Live Fire Setting.
Not having permission to test actual client documents, we turned to the Jeb Bush email set, which was put together by NIST for its annual Text Retrieval Conference. TREC, as it is called, is a large research conference that tests the effectiveness of AI systems.
The Bush collection consists of 300,000 emails from Jeb Bush’s two terms as governor of Florida. He made the corpus public before his run for President. Conference organizers analyzed the documents and came up with 34 different topics to test the algorithms. For each, they identified relevant documents to be used as a gold standard by the participants.
Here is an example topic description:
Slot Machines–All documents concerning the definition, legality, and licensing of “slot machines” in Florida.
The goal for TREC participants was to use their algorithms to find the relevant documents for each topic. The algorithms assumed the availability of human reviewers to judge the documents, and the program organizers developed a system to simulate human review for that purpose. The question in each case was how efficient each TAR algorithm was at finding relevant documents, learning from individual document judgments from the simulated reviewer.
Our goal was substantially different. Rather than determine how quickly the GPT algorithm was at aiding human review, we wanted to see how good it was at replacing human reviewers. GPT would not be provided with human feedback. It had to work only with the topic description. Our metric for each of the 34 TREC topics–in Pokemon vernacular–was “Gotta Catch ‘Em All.”
Methodology: Sending the Documents to GPT for Review
The GPT algorithm is pre-trained on a massive amount of publicly available text and is famously able to answer questions on this data. The algorithm does not, however, allow us to load a new collection of documents, such as the Bush emails. That means we can’t ask the GPT server broad questions about the Bush emails or use it for TAR or typical ediscovery needs.
Instead, we took a different approach, one we briefly explored in our previous article. We send each document, one at a time, to GPT, along with a topic description, and ask GPT whether the document is relevant to that topic. We also ask GPT the reasoning behind its relevance decision.
This combination of document, topic, and instruction makes up what is known in GPT parlance as a “prompt.” Our prompt looked like this:
Here is an email from Jeb Bush’s time as governor of Florida:
<< TEXT OF EMAIL GOES HERE >>
Is this email relevant to the follow topic:
<< TEXT OF TOPIC GOES HERE >>
Answer (yes/no/maybe), then briefly state your reasoning (25-40 words)
Here were GPT’s responses for two documents relating to the Slot Machines topic:
- Yes. This email discusses a proposed initiative petition to amend the Florida Constitution to provide authorization for county voters to approve or disapprove slot machines within existing pari-mutuel facilities. It also mentions the Attorney General’s questions concerning the ballot summary and single-subject requirement.
- No. This email does not discuss slot machines or their legality in Florida. It is about a dispute between a private business owner and the Miccosukee tribe.
That was pretty impressive. We were off to the races.
Matching GPT’s Judgments to the Gold Standard
We took as our gold standard the relevance judgments made for TREC. These were made in three categories: highly relevant; relevant; and irrelevant. We used these as the “answer sheet” for testing GPT’s review capabilities.
One limit we faced was the practical impossibility of sending 300,000 documents for each of the 34 topics to GPT for testing. That would require us to make over ten million submissions and we didn’t have enough beta credits to do that.
Instead, for each topic, we randomly sampled 20 documents from highly relevant documents, 20 from the relevant, and 40 from the not relevant. This reduced the number of submissions to a manageable number, requiring GPT to review and judge a little under 3,000 documents. We could then use sampling theory to extrapolate the results from the sample estimate what would have happened on the full collection.
The Results:
Here are the results of our experiments:
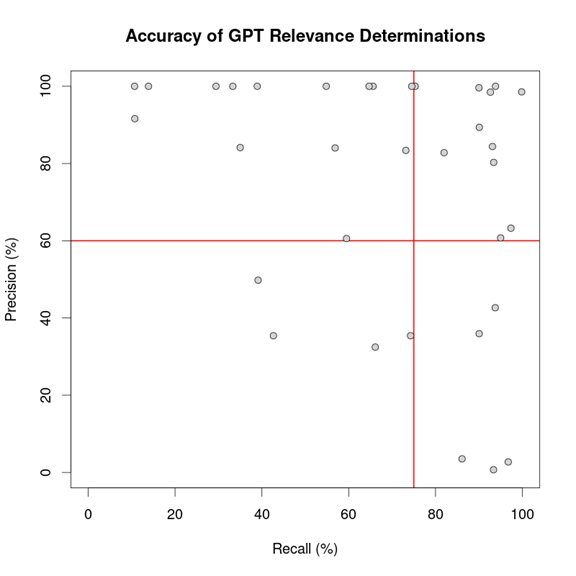
Each dot in the above diagram represents one of the 34 topics we submitted to GPT. We scored review effectiveness of GPT on each topic by two factors:
- What percentage of relevant documents (based on the TREC judgments) GPT judged to be relevant (recall); and
- What percentage of the documents GPT judged to be relevant actually were properly tagged according to the TREC reviewers (precision).
In cases where GPT returned a decision of “maybe,” we treated this as a judgment of “relevant.” There were only 3 documents for which GPT did this.
We overlay grid lines in red showing indicative acceptable levels of recall and precision. The recall line is at 75%, which, as we mentioned earlier, has been viewed by courts as an acceptable level for a document production. We set precision at 60%, which is typically better than what you might get in a keyword review but achievable if the review used a good TAR engine.
You can see how GPT did against both of these objectives.
For four topics, GPT achieved low levels of recall as well as precision. These are displayed in the bottom left quadrant of the chart.
For 14 topics, GPT achieved high precision but recall below our threshold (though two came close). That meant that GPT was accurate in identifying certain relevant documents but failed to find many others. This wasn’t an entirely satisfactory result either. You can find them at the top left of the chart.
For the five topics in the lower right quadrant, GPT achieved close to 100% recall but with low precision. This result would necessarily run up the bill in a traditional review because the humans would have to wade through a lot of irrelevant documents. However these would meet court requirements for sufficient recall.
For the last 11 topics, GPT achieved good levels of recall and precision. These match or exceed what one might expect in a traditional TAR and/or human review process and are quite promising. All told, in this first run GPT achieved effective total performance in a third of the topics (11 out of 34), and passed the grade on recall on over half (19 out of 34).
That got us excited. For a beginning reviewer, GPT didn’t do too bad a job.
Can We Make GPT a Better Reviewer?
Naturally, our next question was: “Can we improve on these results?” We think we can.
We start by introducing a concept known as “prompt engineering.” As you have seen, the primary way we communicate with GPT is by a written prompt. The question we asked was this: “Can we improve GPT’s performance through a better prompt?” In other words, could we better frame our question and better describe the topic being explored?
Our experience to date suggests the answer is “Yes.” We modified our figure to illustrate the improvements we believe could be made through prompt engineering:
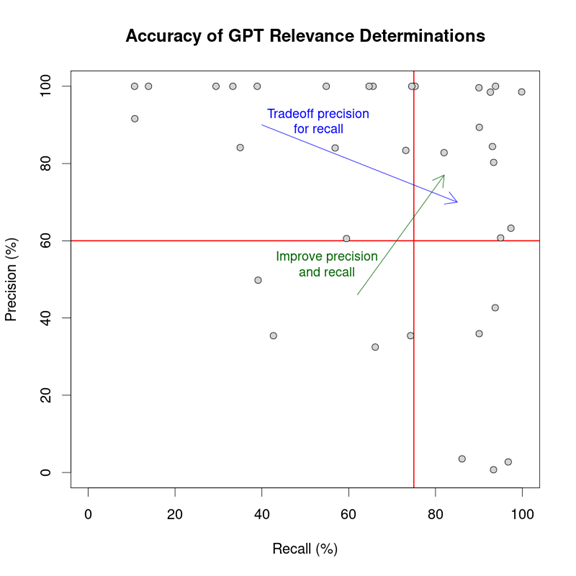
To begin with, we note that for many topics, GPT achieves very high (often 100%) precision, though inadequate recall. This suggests that, for such topics, GPT is being too strict or narrow in its conception of relevance. The conception of relevance could likely be widened, either by loosening the framing language (asking, for instance, whether a document is “partially” relevant, or “seems” relevant, or the like), or by broadening the topic description itself. In this way, it should be possible, with reasonable ease, to trade off a lower precision for a higher recall (the trajectory illustrated by the blue arrow in the figure), while still achieving overall acceptable results.
There are likely also prompt improvements that can increase both recall and precision (the trajectory illustrated by the green arrow above). For instance, we found that the order in asking the question can be important. We concluded that the most effective order based on our limited research was the methodology we used for our experiments and which we described above. That is, we order the prompt as:
- The general context;
- Document text;
- Topic; and
- Instruction.
In previous experiments, we used a different order: “instruction : topic : document.” We found that this made GPT much more likely to sit on the fence with a judgment of “maybe.” We suspect that further improvements are achievable here by the general framing of the prompt, independent of the actual topic being asked. No doubt others are already working on this and can contribute to best practices for GPT prompting.
We also suspect that we could improve the results by better describing the topic at hand. The topic descriptions for the Bush documents were typically short, similar to the topic we described above. In a human review, training would typically involve more extended discussions about the topic, sometimes running to hours of back and forth. While we can’t upload hours of human conversation to GPT, we can provide better descriptions of what we are, and aren’t, looking for as part of the prompt we send to GPT.
Some of these prompt engineering techniques will evolve as we and others gain a better understanding of GPT and how it generally works. Others might be made interactively as the project goes by examining test statistics and individual failure cases for the actual topic and collection under review.
Finally, even if GPT alone is not able to achieve acceptable effectiveness on a given matter, it could be used in combination with TAR to ferret out false positives or additional relevant documents. For instance, where GPT achieves high precision but only moderate recall, we could use it to identify a large initial set of relevant material. From this relevant material, we could train a predictive model, and use it to help identify the rest. Reviewers would be involved in this process but only looking at a much smaller fraction of the total population.
Likewise, we could use a good TAR engine as a QC tool. We would start by building a model on a set of reliable relevant (and perhaps non-relevant) documents identified by GPT (and possibly sampled and verified by human reviewers). We would then ask the TAR algorithm to identify documents it thinks are improperly tagged. These could quickly be identified and properly tagged.
This may seem like a Rube Goldberg type process in that it involves more than just the single step of sending the documents to GPT. However, most computing involves multi-step processes like this but it gets the job done quickly and efficiently. The end result of a multi-modal process like this could be substantial savings in review costs and time–with no reduction in the quality of review.
What About Hallucinations?
Anyone who has read about ChatGPT knows that it can make up answers, sometimes out of whole cloth. Some call these events“hallucinations.” In our last article, we talked about one such example in which ChatGPT attributed a popular book called “TAR for Smart People” to two prominent ediscovery authors–but not the actual author (who happens to be one of the authors of this article). There are lots of these examples. Many are quite funny to read.
Can GPT hallucinate during document review? Actually we found five reviews that can only be described as hallucinations. Interestingly, they happened only in two topics which are found in the bottom right of the quadrant (high recall but low precision). Four occurred in one such topic; one in the other.
Essentially, in these hallucinatory reviews, GPT judged documents as relevant when they clearly were not, and then gave a specious but wrong justification for this judgment. For example, on the topic:
James V. Crosby — All documents concerning James V. Crosby, including but not limited to his relationship with Governor Bush before being appointed as Florida Secretary of Corrections, his role as Secretary, his firing, and any criminal allegations against Mr. Crosby.
GPT returned the following reasoning for declaring one of the documents relevant:
Yes. This email is relevant to the topic as it mentions AHCA, which is the Agency for HealthCare Administration, and WAGES, which is the Workforce and Agency for Gainful Employment Services. Both of these organizations were under the purview of James V. Crosby when he was “Secretary of Corrections.
The summary is an accurate description of the email, and GPT even expanded the acronyms correctly, but the reasoning is entirely fallacious. Neither agency (from what we can tell) was under, or had much to do with, the Secretary of Corrections.
In another email for the same topic, GPT hallucinated that an entirely unconnected, wealthy female philanthropist “was likely involved in the appointment of James V. Crosby as Florida Secretary of Corrections.” In a third, it reasoned that a “Jim” and, separately, a “C” in a short-hand email about legislators, referred to James Crosby. And in a fourth email, GPT confused James Crosby with Jerry Regier, the Secretary for Children and Families. (For one document on another topic, GPT boldly, but incorrectly, asserted that Scripps, a biomedical research institute, was part of the space program.)
Can better prompt engineering help avoid these types of problems? The fact that four of the five problem responses occurred for a single topic suggests that hallucinatory relevance judgments are topic-related, and might be alleviated by modification of the topic description or instructions. (Other users have found that simply telling ChatGPT “don’t make things up” can nudge it back towards the straight and narrow.) Or perhaps the forthcoming, more powerful GPT-4 model will help. Failing that, for some topics GPT may have to be sanity-checked against other human and AI-based QC methods.
Conclusion
We started this article with the question, “Could GPT replace human reviewers?”. The answer is: “potentially yes, with appropriate guidance”. On a substantial proportion of topics, GPT achieved human-level quality of review, at a fraction of the cost and time. Where it fell short, there is good reason to believe that results could be improved by more detailed topic descriptions and better-crafted prompts. And, we are confident that other AI algorithms, including those used for TAR, can be integrated to quickly and efficiently improve the results.
To be sure, in some cases GPT hallucinated specious reasons for finding irrelevant documents relevant. When it does, there is a risk of it filling up the “relevant” pile with its idle fancies. All of these issues require further exploration in the lab and likely will require expert monitoring in the field, at least for the time being.
Why does this matter? Because the cost of civil litigation is too high and ediscovery makes up a large portion of those costs. If we can use artificial intelligence programs to reduce a major component of ediscovery costs, we can help make access to justice more affordable. After all, ediscovery, while important, is not the primary purpose for the litigation process. It is only a sideshow for the main event.
Our goal, harkening back to the lawyer, dog and computer joke we offered in our first article, is to help make sure the ediscovery tail doesn’t end up wagging the litigation dog.
About the Authors
John Tredennick (JT@Merlin.Tech) is the CEO and founder of Merlin Search Technologies, a cloud technology company that has developed a revolutionary new machine learning search algorithm called Sherlock® to help people find information in large document sets–without having to master keyword search.
Tredennick began his career as a trial lawyer and litigation partner at a national law firm. In 2000, he founded and served as CEO of Catalyst, an international e-discovery search technology company that was sold to a large public company in 2019. Over the past four decades he has written or edited eight books and countless articles on legal technology topics, spoken on five continents and served as Chair of the ABA’s Law Practice Management Section.
Dr. William Webber (wwebber@Merlin.Tech) is the Chief Data Scientist of Merlin Search Technologies. He completed his PhD in Measurement in Information Retrieval Evaluation at the University of Melbourne under Professors Alistair Moffat and Justin Zobel, and his post-doctoral research at the E-Discovery Lab of the University of Maryland under Professor Doug Oard.
With over 30 peer-reviewed scientific publications in the areas of information retrieval, statistical evaluation, and machine learning, he is a world expert in AI and statistical measurement for information retrieval and ediscovery. He has almost a decade of industry experience as a consulting data scientist to ediscovery software vendors, service providers, and law firms.
[1] This article was originally published by the American Lawyer Media in Law.com on February 21, 2023 and is circulated with permission.

