[Editor’s Note: EDRM is proud to publish Ralph Losey’s advocacy and analysis. The opinions and positions are Ralph Losey’s copyrighted work.]
A first of its kind experiment testing use of AI found a 40% increase in quality and 12% increase in productivity. The tests involved 18 different realistic tasks assigned to 244 different consultants in the Boston Consulting Group. The Harvard Business School has published a preliminary report of the mammoth study. Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on Knowledge Worker Productivity and Quality (Harvard Business School, Working Paper 24-013) (hereinafter “Working Paper”). The Working Paper is analyzed here with an eye on its significance for the legal profession.
Group of consultants tested with AI. Watercolor image by Ralph Losey using Visual Muse: illustrating concepts with style.
My last article, From Centaurs To Cyborgs: Our evolving relationship with generative AI, explained that you should expect the unexpected when using generative AI. It also promised that use of sound hybrid prompt engineering methods, such as the Centaur and Cyborg methods, would bring more delight than fright. The Working Paper provides solid evidence of that claim. It reports on a scientific study conducted by AI experts, work experts and experimental scientists. They tested 244 consultants from the Boston Consulting Group (“BCG”). The Working Paper, although still in draft form, shares the key data from the experiment. Appendix E of the Working Paper discusses the conceptual model of the Centaur and Cyborg methods of AI usage, which I wrote about in From Centaurs To Cyborgs.
The 244 high-level BCG consultants were a diverse group who volunteered from offices around the world. They dedicated substantial time performing the 18 assigned tasks under the close supervision of the Working Paper author-scientists. Try getting that many lawyers in a global law firm to do the same.
Image by Ralph Losey using his Visual Muse: illustrating concepts with style.
The experiment included several important control groups and other rigorous experimental controls. The primary control was the unfortunate group of randomly selected BCG consultants who were not given ChatGPT4. They had to perform a series of assigned tasks in their usual manner, with computers of course, but without a generative AI tool. The control group comparisons provide strong evidence that use of AI tools on appropriate consulting taskssignificantly improve both quality and productivity.
That qualification of “appropriate tasks” is important and involves another control group of tasks. The scientists designed, and included in the experiment, work tasks that they knew could not be done well with the help of AI, that is, not without extensive guidance, which was not provided. They knew that although these tasks were problematic for ChatGPT4, they could be done, and done well, without the use of AI. Working Paper at pg. 13. Pretty devious type of test for the poor guinea pig consultants. The authors called the tasks assigned that they knew to be beyond ChatGPT4’s then current abilities to be work “beyond the jagged technological frontier.” In the authors’ words:
Our results demonstrate that AI capabilities cover an expanding, but uneven, set of knowledge work we call a “jagged technological frontier.” Within this growing frontier, AI can complement or even displace human work; outside of the frontier, AI output is inaccurate, less useful, and degrades human performance. However, because the capabilities of AI are rapidly evolving and poorly understood, it can be hard for professionals to grasp exactly what the boundary of this frontier might be at a given. (sic)
The improvement in quality for tasks appropriate for GPT4 – work tasks inside the frontier – was remarkable, overall 40%, although somewhat inconsistent between sub-groups as will be explained. Productivity also went up, although to a lesser degree. There was no increase in quality or productivity for workers trying to use GPT4 for tasks beyond the AI’s ability, those outside the frontier. In fact, when GPT4 was used for those outside tasks, the answers of the AI assisted consultants were 19% less likely to be correct. That is an important take-away lesson for legal professionals. Know what LLMs can do reliably, and what they cannot.
The scientists who designed these experiments themselves had difficulty coming up with work tasks that they knew would be outside ChatGPT4’s abilities:
In our study, since AI proved surprisingly capable, it was difficult to design a task in this experiment outside the AI’s frontier where humans with high human capital doing their job would consistently outperform AI.
Working Paper at pg. 19.
It was hard, but the business experts finally came up with a consulting task that would make little ChatGPT4 look like a dunce.
Hard to find a dunce AI to work with smart consultants. Image by Ralph Losey with Visual Muse.
The authors were obtuse in this draft report about the specific tasks “outside the frontier” used in the tests and I hope this is clarified, since it is very important. But it looks like they designed an experiment where consultants with ChatGPT4 would use it to analyze data in a spreadsheet and omit important details found only in interviews with “company insiders.” The AI and consultants relying on the AI were likely to miss important details in the interviews and so make errors in recommendations. To quote the Working Paper at page 13:
To be able to solve the task correctly, participants would have to look at the quantitative data using subtle but clear insights from the interviews. While the spreadsheet data alone was designed to seem to be comprehensive, a careful review of the interview notes revealed crucial details. When considered in totality, this information led to a contrasting conclusion to what would have been provided by AI when prompted with the exercise instructions, the given data, and the accompanying interviews.
Working Paper at page 13.
In other words, it looks like the Working Paper authors designed tasks where they knew ChatGPT4 would likely make errors and gloss over important details in interview summaries. They knew that the human-only expert control group would likely notice the importance of these details in the interviews and so make better recommendations in their final reports. Working Paper, Section 3.2 – Quality Disruptor – Outside the frontier at pages 13-15.
Image by Ralph Losey using his Visual Muse: illustrating concepts with style.
This is comparable to an attorney relying solely on ChatGPT4 to study a transcript of a deposition that they did not take or attend, and ask GPT4 to summarize it. If the attorney only reads the summary, and the summary misses key details, which is known to happen, especially in long transcripts and where insider facts and language are involved, then the attorney can miss key facts and make incorrect conclusions. This is a case of over-delegation to an AI, past the jagged frontier. Attorneys should read the transcript, or have been at the deposition and so recall key insider facts, and thereby be in a position to evaluate the accuracy and completeness of the AI summary. Trust but verify.
The 19% decline in performance for work outside the frontier is a big warning flag to be careful, to go slow at first and know what generative AI can and cannot do well. See: Losey, From Centaurs To Cyborgs (4/24/24). Humans must remain the loop for many of the tasks of complex knowledge work.
Still, the positive findings of increased quality and productivity for appropriate tasks, those within the jagged frontier, are very encouraging to workers in the consulting fields, including attorneys. This large experiment on volunteer BCG guinea pigs provides the first controlled experimental evidence of the impact of ChatGPT4 on various kinds of consulting work. It confirms the many ad hoc reports that generative AI allows you to improve both the quality and productivity of your work, faster and better. You just have to know what you are doing, know the jagged line, and intelligently use both Centaur and Cyborg type methods.
Professionals walking the Jagged Technological Frontier. Image by Ralph Losey and Visual Muse in watercolor style.
Appendix E of the Working Paper discusses these methods. To quote from Appendix E – Centaur and Cyborg Practices:
By studying the knowledge work of 244 professional consultants as they used AI to complete a realworld, analytic task, we found that new human-AI collaboration practices and reconfigurations are emerging as humans attempt to navigate the jagged frontier. Here, we detail a typology of practices we observed, which we conceptualize as Centaur and Cyborg practices.
Centaur behavior. … Users with this strategy switch between AI and human tasks, allocating responsibilities based on the strengths and capabilities of each entity. They discern which tasks are best suited for human intervention and which can be efficiently managed by AI. From a frontier perspective, they are highly attuned to the jaggedness of the frontier and not conducting full sub-tasks with genAI but rather dividing the tasks into sub-tasks where the core of the task is done by them or genAI. Still, they use genAI to improve the output of many sub-tasks, even those led by them.
Cyborg behavior. … Users do not just have a clear division of labor here between genAI and themselves; they intertwine their efforts with AI at the very frontier of capabilities. This manifests at the subtask level, when for an external observer it might even be hard to demarcate whether the output was produced by the human or the AI as they worked tightly on each of the activities related to the sub task.
Working Paper, Appendix E – Centaur and Cyborg Practices:
As discussed at length in my many articles on generative AI, close supervision and verification is required from most of the work by legal professionals. It is an ethical imperative. For instance, no new case found by AI should ever be cited without human verification. The Working Paper calls this blurred division of labor Cyborg behavior.
Cyborg style close supervision of AI is required in legal applications. Shown in modern digital style, by Ralph Losey using Visual Muse GPT: illustrating concepts with style.
Excerpts from the Working Paper
Here are a few more excerpts from the Working Paper and a key chart. Readers are encouraged to read the full report. The details are important, as the outside the frontier tests showed. I begin with a lengthy quote from the Abstract. (The image inserted is my own, generated using my GPT for Dall-E, Visual Muse: illustrating concepts with style.)
In our study conducted with Boston Consulting Group, a global management consulting firm, we examine the performance implications of AI on realistic, complex, and knowledge-intensive tasks. The pre-registered experiment involved 758 consultants comprising about 7% of the individual contributor-level consultants at the company. After establishing a performance baseline on a similar task, subjects were randomly assigned to one of three conditions: no AI access, GPT-4 AI access, or GPT-4 AI access with a prompt engineering overview.
We suggest that the capabilities of AI create a “jagged technological frontier” where some tasks are easily done by AI, while others, though seemingly similar in difficulty level, are outside the current capability of AI.
Image: Ralph Losey using Visual Muse GPT.
For each one of a set of 18 realistic consulting tasks within the frontier of AI capabilities, consultants using AI were significantly more productive (they completed 12.2% more tasks on average, and completed tasks 25.1% more quickly), and produced significantly higher quality results (more than 40% higher quality compared to a control group). Consultants across the skills distribution benefited significantly from having AI augmentation, with those below the average performance threshold increasing by 43% and those above increasing by 17% compared to their own scores.
For a task selected to be outside the frontier, however, consultants using AI were 19 percentage points less likely to produce correct solutions compared to those without AI. Further, our analysis shows the emergence of two distinctive patterns of successful AI use by humans along a spectrum of human-AI integration. One set of consultants acted as “Centaurs,” like the mythical half-horse/half-human creature, dividing and delegating their solution-creation activities to the AI or to themselves. Another set of consultants acted more like “Cyborgs,” completely integrating their task flow with the AI and continually interacting with the technology.
Working Paper.
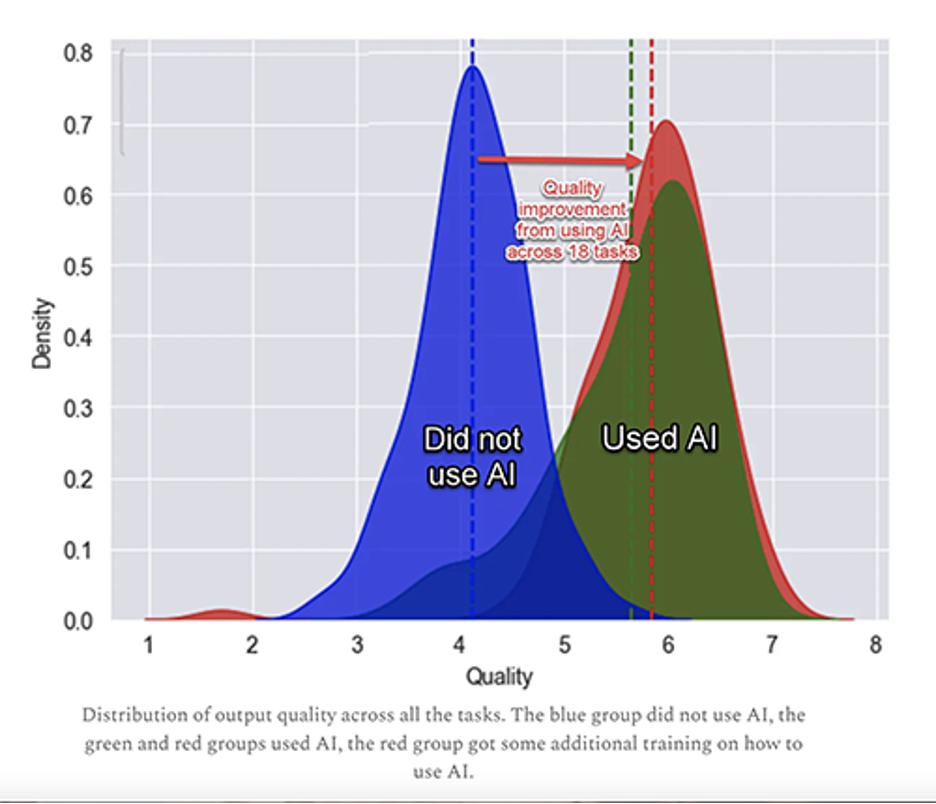
Key Chart Showing Quality Improvements
The key chart in the Working Paper is Figure 2, found at pages 9 and 28. It shows the underlying data of quality improvement. In the words of the Working Paper:
Figure 2 uses the composite human grader score and visually represents the performance distribution across the three experimental groups, with the average score plotted on the y-axis. A comparison of the dashed lines and the overall distributions of the experimental conditions clearly illustrates the significant performance enhancements associated with the use of GPT-4. Both AI conditions show clear superior performance to the control group not using GPT-4.
The version of the chart shown below has additions by one of the coauthors, Professor Ethan Mollick (Wharton), who put the red arrow comments not found in the published version. (Note the “y-axis” in the chart is the vertical scale labeled “Density.” In XY charts “Density” generally refers to distribution of variables, i.e. probability of data distribution. The horizontal “x-axis: is the overall quality performance measurement.)
Image: Graph by Professor Mollick.
Professor Mollick provides this helpful highlight of the main findings of the study, both quality and productivity:
[F]or 18 different tasks selected to be realistic samples of the kinds of work done at an elite consulting company, consultants using ChatGPT-4 outperformed those who did not, by a lot. On every dimension. Every way we measured performance. Consultants using AI finished12.2% more tasks on average, completed tasks 25.1% more quickly, and produced 40% higher quality results than those without. Those are some very big impacts.
I was surprised at first to see that the quality of the “some additional training group” did not go up more than the approximate 8% shown in the chart. In digging deeper I found a YouTube video by Professor Mollick on this study where he said at 19:14 that the training, which he created, only consisted of a five to ten minute seminar. In other words, very cursory and yet it still had an impact on performance.
AI Training Session in digital art photorealistic style by Ralph Losey using Visual Muse.
Another thing to emphasize about the study is how carefully the tasks for the tests were selected and how realistic the challenges were. Again, here is a quote from Ethan Mollick‘s excellent article. Centaurs and Cyborgs on the Jagged Frontier, (One Useful Thing, 9/16/23). Also see Mollick’s interesting new book, Co-Intelligence: Living and Working with AI (4/2/24).
To test the true impact of AI on knowledge work, we took hundreds of consultants and randomized whether they were allowed to use AI. We gave those who were allowed to use AI access to GPT-4 . . . We then did a lot of pre-testing and surveying to establish baselines, and asked consultants to do a wide variety of work for a fictional shoe company, work that the BCG team had selected to accurately represent what consultants do. There were creative tasks (“Propose at least 10 ideas for a new shoe targeting an underserved market or sport.”), analytical tasks (“Segment the footwear industry market based on users.”), writing and marketing tasks (“Draft a press release marketing copy for your product.”), and persuasiveness tasks (“Pen an inspirational memo to employees detailing why your product would outshine competitors.”). We even checked with a shoe company executive to ensure that this work was realistic – they were. And, knowing AI, these are tasks that we might expect to be inside the frontier.
Ethan Mollick, Centaurs and Cyborgs on the Jagged Frontier, (One Useful Thing, 9/16/23).
Most of the tasks listed for this particular test do not seem like legal work, but there are several general similarities. For example, the creative task of brainstorming of new ideas, the analytical tasks and the persuasiveness tasks. Legal professionals do not write inspirational memos to employees, like BCG consultants, but we do write memos to judges trying to persuade them to rule in our favor.
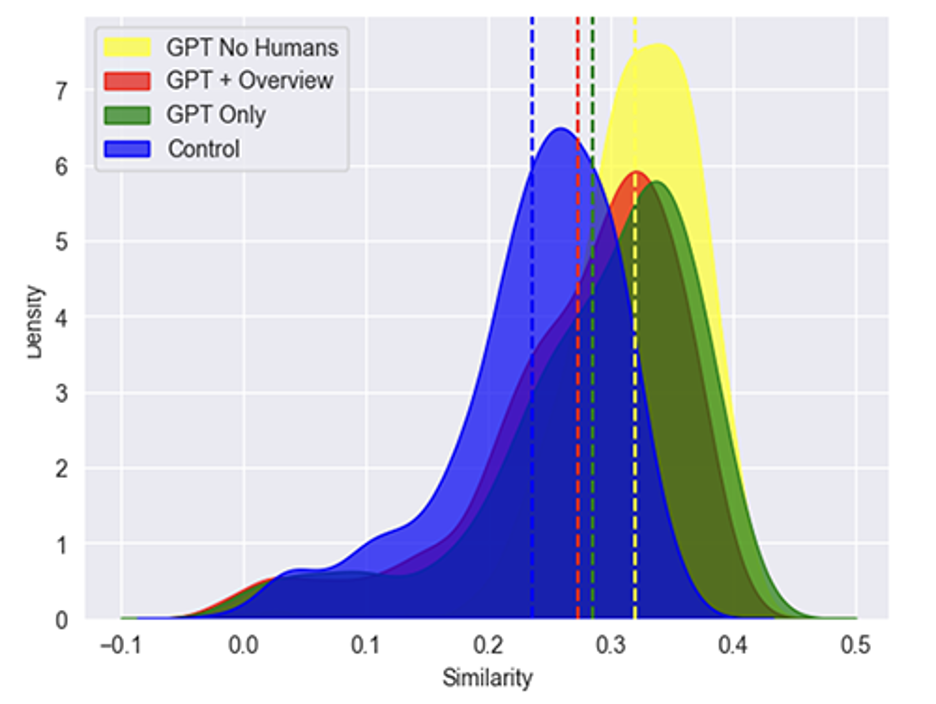
Another surprising finding of the Working Paper is that use of ChatGPT by BCG consultants on average reduced the range of ideas that the subjects generated. This is shown in the below Figure 1.
Graph by Professor Mollick.
Figure 1. Distribution of Average Within Subject Semantic Similarity by experimental condition: Group A (Access to ChatGPT), Group B (Access to ChatGPT + Training), Group C (No access to ChatGPT), and GPT Only (Simulated ChatGPT Sessions).
We also observe that the GPT Only group has the highest degree of between semantic similarity, measured across each of the simulated subjects. These two results taken together point toward an interesting conclusion: the variation across responses produced by ChatGPT is smaller than what human subjects would produce on their own, and as a result when human subjects use ChatGPT there is a reduction in the variation in the eventual ideas they produce. This result is perhaps surprising. One would assume that ChatGPT, with its expansive knowledge base, would instead be able to produce many very distinct ideas, compared to human subjects alone. Moreover, the assumption is that when a human subject is also paired with ChatGPT the diversity of their ideas would increase.
While Figure 1 indicates access to ChatGPT reduces variation in the human-generated ideas, it provides no commentary on the underlying quality of the submitted ideas. We obtained evaluations of each subject’s idea list along the dimension of creativity, ranging from 1 to 10, and present these results in Table 1. The idea lists provided by subjects with access to ChatGPT are evaluated as having significantly higher quality than those subjects without ChatGPT. Taken in conjunction with the between semantic similarity results, it appears that access to ChatGPT helps each individual construct higher quality ideas lists on average; however, these ideas are less variable and therefore are at risk of being more redundant.
Working Paper, Figure 1.
So there is hope for creative brainstormers, at least with GPT4 level of generative AI. Generative AI is clearly more redundant than humans. As quoted in my last article, Professor Mollick says they are a bit homogenous and same-y in aggregate. Losey, From Centaurs To Cyborgs: Our evolving relationship with generative AI (04/24/24). Great phrase that ChatGPT4 could never have come up with.
Also see: Mika Koivisto and Simone Grassini, Best humans still outperform artificial intelligence in a creative divergent thinking task (Nature, Scientific Reports, 2/20/24) (“AI has reached at least the same level, or even surpassed, the average human’s ability to generate ideas in the most typical test of creative thinking. Although AI chatbots on average outperform humans, the best humans can still compete with them.“); Losey, ChatGPT-4 Scores in the Top One Percent of Standard Creativity Tests (e-Discovery Team, 7/21/23) (“Generative Ai is still far from the quality of the best human artists. Not yet. … Still, the day may come when Ai can compete with the greatest human creatives in all fields. … More likely, the top 1% in all fields will be humans and Ai working together in a hybrid manner.”).
AI As a ‘Skill Leveler’
As mentioned, the improvement in quality was not consistent between subgroups. The consultants with the lowest pre-AI tests scores improved the most with AI. They became much better than they were before. The same goes for the middle of the pack pre-AI scorers. They also improved, but by a lesser amount. The consultants at the top end of pre-AI scores also improved, but by an even smaller amount than those behind them. Still, with their small AI improvements, the pre-AI winners maintained their leadership. The same consulting experts still outscored everyone. No one caught up with them. What are the implications of this finding on future work? On training programs? On hiring decisions?
Three levels of computer competence in detailed photographic style by Ralph Losey using Visual Muse. Is that a Gordian Knot in his hands?
Here is Professor Ethan Mollick’s take on the significance of this finding.
It (AI) works as a skill leveler. The consultants who scored the worst when we assessed them at the start of the experiment had the biggest jump in their performance, 43%, when they got to use AI. The top consultants still got a boost, but less of one. Looking at these results, I do not think enough people are considering what it means when a technology raises all workers to the top tiers of performance. It may be like how it used to matter whether miners were good or bad at digging through rock… until the steam shovel was invented and now differences in digging ability do not matter anymore. AI is not quite at that level of change, but skill leveling is going to have a big impact.
My only criticism of Professor Mollick’s analysis is that it glosses over the differences that remained after AI between the very best, and the rest. In the field I know, law, not business consulting, the differences between the very good, the B or B+ lawyers, and great lawyers, the A or A+, is still very significant. All attorneys with skill levels in the B – A+ range can legitimately be considered top tier legal professionals, especially as compared to the majority of lawyers in the average and below average range. But the impact of these skill differences on client services can still be tremendous, especially in matters of great complexity or importance. Just watch when two top tier lawyers go against each another in court, one good and one truly great.
Image: Ralph Losey using Visual Muse.
Further Analysis of Skill Leveling
What does the leveling phenomena of “average becoming good” mean to the future of work? Does it mean that every business consultant with ChatGPT will soon be able to provide top tier consulting advice. Will every business consultant on the street with ChatGPT soon be able to “pen an inspirational memo to employees detailing why your product would outshine competitors“? Will their lower priced memos be just as good as top tier BCG memos? Is generative AI setting the stage for a new type of John Henry moment for knowledge workers, as Professor Mollick suggests? Will this near leveling of the playing field hold true for all types of knowledge workers, not only business consultants, but also doctors and lawyers?
To answer these questions it is important to note that the results in this first study on business consultant work does not show a complete leveling. Not all of the consultants became John Henry superstars. Instead, the study showed the differences continued, but were less pronounced. The gap narrowed, but did not disappear. The race only became more competitive.
Moreover, the names of the individual winners and also-rans remained the same. It is just that the “losers” (seems like too harsh a term) now did not “lose” by as much. In the race to quality the same consultants were still leading, but the rest of the pack was not as far behind. Everyone got a boost, even the best. But will this continue as AI advances? Or eventually will some knowledge workers do far better with the AI steam hammers or shovels than others, no matter where they started out? Moreover, under what circumstances, including pricing differentials, do consumers choose the good professionals who are not quite as good as those on the medalist stand?
Good, very good and great with AI enhancement. Does the public even know the difference? Image: Ralph Losey’ using Visual Muse.
The study results show that the pre-AI winners, those at the very top of their fields before the generative AI revolution, were able to use the new AI tools as well as the others. For that reason, their quality and productivity were also enhanced. They still remained on top, still kept their edge. But in the future, assuming AI gets better, will that edge continue? Will there be new winners and also-rans? Or eventually will everyone tie for first, at least in so far as quality and productivity are concerned? Will all knowledge workers end up the same, all equal in quality and productivity.
That seems unlikely, no matter how good AI gets. I cannot see this happening anytime soon, at least in the legal field. (I assume the same is also true for the medical field.) In law the analysis and persuasion challenges are far greater than those in most other knowledge fields. The legal profession is far too complex for AI to create a complete leveling of performance, at least not in the foreseeable future. I expect the differentials among medical professionals will also continue.
Moreover, although not studied in this report, it seems obvious that some legal workers will become far better at using AI than others. In this first study of business consultants, all started on the same level of inexperience using generative AI. Only a few were given training. The training provided, only five to ten minutes, was still enough to move the needle. The control group with this almost trivial amount of training did perform better, although not enough to close the gap.
With significant training, or experience, the improvements should be much greater. Maybe quality will increase by 70%, instead of the 40% we saw with little or no training. Maybe productivity will increase by at least 50%, instead of just 12%. That is what I would expect based on my experience with lawyers since 2012 using predictive coding. After lawyer skill-sets develop for use of generative AI, all of the performance metrics may soar.
Image: Ralph Losey with Visual Muse.
Conclusion
In this experiment where some professionals were given access to ChatGPT4 and some were not, a significant, but not complete leveling of performance was measured. It was not a complete leveling because the names at the very top of the leaderboard of quality and productivity remained the same. I believe this is because the test subjects were all ChatGPT virgins. They had not previously learned prompt engineering methods, even the beginning basics of Centaur or Cyborg approaches. It was all new to them.
As part of the experiment some were given ten minutes of basic training in prompt engineering and some were given none. In the next few years some professionals will receive substantial GPT training and attain mastery of the new AI tools. Many will not. When that happens, the names on the top of the leaderboard will likely change, and change dramatically.
Leaderboard of Knowledge Workers in Watercolor by Ralph Losey using Visual Muse
History shows that times of great change are times of opportunity. The deck will be reshuffled. Who will learn and readily adapt to the AI enhancements and who will not? Which corporations and law firms will prosper in the age of generative AI, and which will fail? The only certainty here is the uncertainty of surprising change.
In the future every business may well have access to top tier business consultants. All may be able to pen an inspirational memo to employees. But will this near leveling between the best, and the rest, have the same impact on the legal profession? The medical profession? I think not. Especially as some in the profession gain skills in generative AI much faster than others. The competition between lawyers and law firms will remain, but the names on the top of the leader board will change.
From a big picture perspective the small differentials between good and great lawyers are not that important. Of far greater importance is the likely social impact of the near leveling of lawyers. The gain in skills of the vast majority of lawyers will make it possible, for the first time, for high quality legal services to become available to all.
Consumer law and other legal services could become available to everyone, at affordable rates, and without a big reduction in quality. In the future, as AI creates a more level playing field, the poor and middle class will have access to good lawyers too. These will be affordable good lawyers who, when ethically assisted by AI, are made far more productive. This can be accomplished by responsible use of AI. This positive social change seems likely. Equal justice for all will then become a common reality, not just an ideal.
EQUAL JUSTICE FOR ALL. Finally attained by use of AI. Watercolor conceptual art using Visual Muse GPT by Ralph Losey.
Ralph Losey Copyright 2024 — All Rights Reserved. See applicable Disclaimer to the course and all other contents of this blog and related websites. Watch the full avatar disclaimer and privacy warning here.
Ralph Losey is the creator of QUANTUM LAW: From Causation to Probability, a self-paced course on AI, quantum computing, evidence, cybersecurity, privacy, and legal judgment, and author of the e-Discovery Team blog, established in 2006.
Ralph Losey is a lawyer, tech researcher, educator and writer. After 45-years of legal practice with several local and national law firms, Ralph retired in 2026. He continues his service to the profession as CEO of Losey AI, LLC, providing non-legal educational services on AI and quantum law.
Ralph has long been a leader among the world's tech lawyers. He has presented at hundreds of legal conferences and CLEs around the world and written over two million words on AI, e-discovery, quantum and other tech-law subjects, including seven books.
Ralph has been involved with computers, software, legal hacking, and the law since 1980. Ralph had the highest peer AV rating as a lawyer and was consistently selected as a Best Lawyer in America in four categories: E-Discovery and Information Management Law, Information Technology Law, Commercial Litigation, and Employment Law - Management. For his full resume and list of publications, see his e-Discovery Team Blog.
Ralph has been married to Molly Friedman Losey, a mental health counselor in Winter Park, since 1973 and is the proud father of two children and grandfather of two more.
With deep sadness, we share the loss of Kaylee Walstad, Chief Strategy Officer of EDRM and an extraordinary advocate, mentor, and friend to so many in the eDiscovery and legal technology community. Kaylee’s generosity, encouragement, and compassion touched countless lives, and her legacy lives on in the people and organizations she lifted.
To honor Kaylee’s remarkable life and lasting contributions, we invite you to share your own memories, reflections, and images. Your tributes will help celebrate the joy she brought to others and the light she shared so freely with everyone she encountered.