

[EDRM Editor’s Note: The opinions and positions are those of John Tredennick, Dr. William Webber and Lydia Zhigmitova.]
The legal industry is witnessing a revolution with the adoption of AI for its core functions. There are hundreds, if not thousands, of new software applications using generative AI. Most use OpenAI’s latest large language model (LLM), GPT-4, and are seemingly locked into one vendor and one model.
We chose a different approach for DiscoveryPartner, our GenAI ediscovery platform. It can access GenAI products from multiple vendors for different tasks. Why do this? Because it affords the flexibility to use the best, most cost-effective LLM for each task required. And it avoids keeping all our eggs in one AI basket.
As you will quickly see, it’s a much smarter way to go.
Why Build a Multi-LLM Framework?
We chose to build a multi-LLM framework because we have found that lower-priced LLM models can handle certain tasks as well as the higher-priced version and often do them much more quickly.
A multi-LLM framework provides our clients with the flexibility to use different LLM models for different purposes. And it also allows them to use faster and cheaper models for routine work, while reserving the most sophisticated (and expensive) models for synthesis, analysis and reports. This approach is faster, more flexible and more cost-effective than relying on a single model from a single vendor.
How Does a Multi-LLM System Work?
DiscoveryPartner uses different LLM providers for document analysis, including OpenAI, Microsoft and Anthropic. Supporting two key functions for document analysis, summarization and synthesis, DiscoveryPartner illustrates a new paradigm in legal investigations.
Document Summarization
Once relevant documents are identified, the user can direct the system to summarize based on a topic description. We typically use the LLM first to summarize documents based on a topic request. We then submit multiple summaries to the LLM for analysis rather than the entire document. This lets us submit more summaries to the LLM for analysis than would be possible if we submitted entire documents.
Specifically, you tell the LLM about the nature of your investigation and the kind of information you want to review. You might also ask it to identify people and dates mentioned in the document.
DiscoveryPartner offers these options for document summarization:
We have found that Claude Instant (100 K) is quick, efficient and provides document summary content that is roughly equivalent to the output from GPT-4. In fact, Claude Instant is faster at producing summaries and costs a fraction of what you pay for GPT-4 to provide the same function. For that reason we recommend using Claude Instant, particularly when you are summarizing 300 or more documents.
There is a second reason we like Claude Instant for summarization work. It has a much larger context window (100K tokens vs. 4K or 16K with GPT-4). That makes it perfect for analyzing larger documents that won’t fit in a smaller context window.
Synthesis and Reporting
The second step is to synthesize and report on information across the documents selected for summarization. This typically involves a high-level analysis of the documents tailored to your information need and more complex reporting requests.
For synthesizing and reporting across multiple documents, we recommend top-of-the-line LLMs like GPT-4 and Claude 2, which excel in providing insightful reports on legal issues, positions, people involved and timelines. Both cost more than their alternative versions and are a bit slower at responding to requests, but the higher quality output makes it worth putting up with both of these small issues.
How Much Can A Multi-LLM Save Us In Processing Costs?
Many of us started using ChatGPT when it was free. Some of us moved to the $20 per month version to secure faster responses and access to later models but daily volumes were still limited. These licenses aren’t suitable for commercial purposes and are not our focus here.
For legal systems, we need to move to a commercial license and access GPT, the underlying engine for ChatGPT, through an API (application programming interface).
Before we get to specific prices for different models, let’s talk a bit about tokens. They are central to the analysis of which models are best suited for different purposes.
About Tokens
Tokens are the basic units of text or code that an LLM uses to process and generate language. Tokens can be punctuation, words, subwords or other segments of text or code. A token count of 1,000 typically equates to about 750 English language words.
How many tokens in a prompt? This obviously depends on the length of information you send to the LLM. For our purposes, however, prompt lengths can be long because we typically send the text of ediscovery documents (or summaries of that text) to the LLM along with our request or question.
Why send the text? Because, for ediscovery at least, we typically ask the LLM to base its answer on the text of one or more discovery documents (email, documents, transcripts, etc.). As a result, the volume of text transmitted to the LLM can be much larger than the response.
For pricing purposes, we have found that the average volume of prompts is roughly ten times larger than the average volume of responses. Put another way, we typically send 1,000 tokens to the system for every 100 tokens received in response.
Why does this matter? Because most vendors charge one price for the volume of tokens submitted in the prompt (input) and another, larger price for the volume of tokens returned by the LLM in its answer (output).
Commercial Pricing
Here is a chart showing current pricing for two different LLMs: GPT (from OpenAI and Microsoft) and Claude 2 (from 1Anthropic).12 Both GPT and Claude come in different models, with pricing matching their capabilities. Microsoft and OpenAI offer the same prices so they are grouped3 together2.
| Comparative Pricing for GPT and Claude 2 | |||
| LLM Model | Prompt (per 1,000 tokens) | Completion (per 1,000 tokens) | Cost per Document Processed |
| GPT-3.5 Turbo (4K) | $0.0015 | $0.0020 | $0.0034 |
| Claude Instant (100K) | $0.0016 | $0.0055 | $0.0044 |
| GPT-3.5 Turbo (16K) | $0.0030 | $0.0040 | $0.0068 |
| Claude 2 (100K) | $0.0110 | $0.0327 | $0.0286 |
| GPT-4 (8K) | $0.0300 | $0.0600 | $0.0720 |
| GPT-4 (32K) | $0.0600 | $0.1200 | $0.1440 |
The references in parentheses represent the size of the context window for each model. In essence, the context window limits how large the prompt can be for each request. The higher the prompt limit, the better, but costs increase as well. You can read more about context windows here: Are LLMs Like GPT Secure?
Prices per 1,000 tokens are relatively small. To put things in perspective, we estimated the cost to send and return information for a single document that is 2,000 tokens in length (about 1,500 words). This is a representative average document length for ediscovery, though it will vary between cases and collections.
You can quickly see that the cost to use GPT-4 is much greater than for lesser models like GPT 3.5. This chart shows relative pricing as a multiple of the cheapest model: GPT 3.5 (4K):
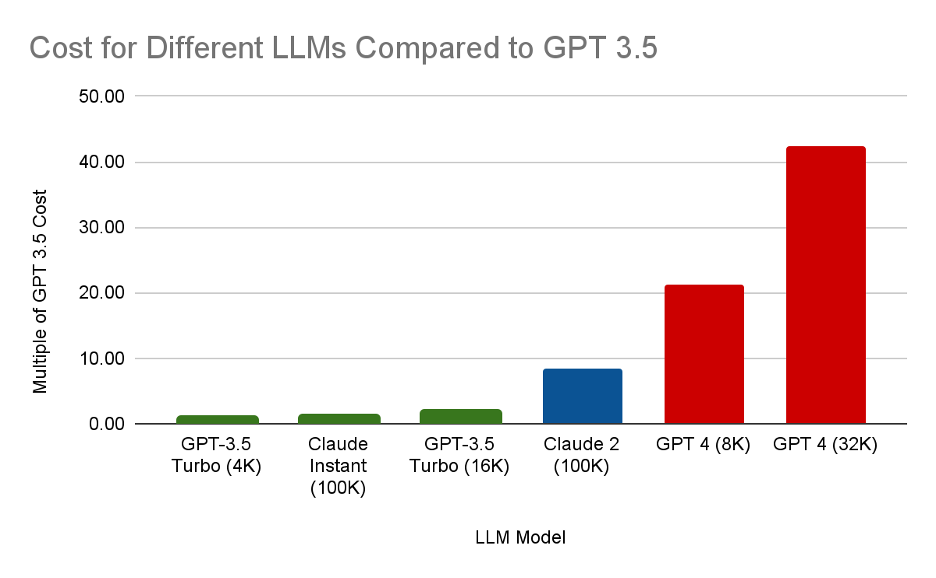
GPT-4 (32K) costs over 40 times more than GPT 3.5. GPT-4 (8K) costs over 20 times more than GPT 3.5. Do we need the power of GPT-4 for every task we might run? That is the question we will address in the next section.
Getting Smart About How We Use LLMs
As we pointed out, using different LLMs for different jobs affords the flexibility to use the best, most cost-effective LLM for each task required. Pricing can make a difference when two tools can do the same job equally well. If one of the LLMs costs fifty times more than the other, you might want to pay attention.
With a multi-LLM framework, our clients can mix and match LLMs and individual models to get the most cost-effective results. Here is a chart showing how this approach can save on LLM costs using different combinations of LLMs and models.
| Cost of Different LLM Combinations Over 1,000 Documents | |||||
| Summary LLM | Reporting LLM | Summary Costs Per 1,000 Documents | Reporting Costs Per 1,000 Documents | Total Cost Per 1,000 Documents | Total Cost Per 100,000 Documents |
| GPT-3.5 Turbo (4K) | GPT-3.5 Turbo (4K) | $3.40 | $0.30 | $3.70 | $370 |
| Claude Instant (100K) | Claude Instant (100K) | $4.36 | $0.33 | $4.69 | $469 |
| Claude Instant (100K) | GPT 4 (32K) | $4.36 | $12.00 | $16.36 | $1,636 |
| GPT-3.5 Turbo (4K) | GPT 4 (32K) | $3.40 | $12.00 | $15.40 | $1,540 |
| Claude 2 (100K) | Claude 2 (100K) | $28.58 | $2.20 | $30.78 | $3,078 |
| GPT 4 (32K) | GPT 4 (32K) | $144.00 | $12.00 | $156.00 | $15,600 |
You can quickly see how the costs vary between different combinations of LLMs and LLM models. In this case, we have highlighted two combinations that we think represent smart choices. We urge clients to consider GPT 3.5 or Claude Instant for summary work. Why? Because they are much faster than their more powerful siblings and less costly. And, the summaries don’t show the kind of improvement that justify the added costs in most cases. Where a client wants the additional horsepower provided by GPT-4 or Claude 2, it is easy to change the setting.
Why consider Claude Instant or Claude 2 in this mix? One simple reason is the larger context window. Claude 2 offers a three-times larger context window which can be important for large documents. As an example, we can fit most transcripts into Claude Instant or Claude 2. They would have to be broken up to fit GPT’s smaller context window. This can make the difference in many cases. (We are thinking about checking text sizes before processing to automatically send larger documents to Claude 2 even if we use GPT for their analysis.)
Ultimately, the smart play depends on your matter and your documents. The one thing we can say for sure is that having a multi-LLM framework affords the flexibility to use the best, most cost-effective LLM for each task required. That is why we chose a different path than other vendors.
Adding New LLMs
There is one more important advantage to our approach. As new and even more powerful LLMs hit the market, we can integrate them into our platform. We connect to commercial versions of LLMs like GPT and Claude through an API, which provides the flexibility we need to connect and take advantage of different LLMs.
Hardly a week goes by without an announcement of a new “more powerful” large language model that will knock the current AI leaders off their pedestals. As these new LLMs continue to emerge, our adaptable framework ensures that we remain at the forefront of technology, offering our clients an agile, powerful, and economically wise tool that elevates their practice in an increasingly competitive and technologically-driven environment.
Footnotes:
- There are other vendors on the market but these represent the two LLMs we currently use. You can apply the same analysis to different LLMs you may be considering.
↩︎ - GPT pricing is per 1,000 tokens. Anthropic prices per million tokens. For comparative purposes, we normalized pricing using 1,000 tokens for each.
↩︎
Assisted by GAI and LLM Technologies per EDRM GAI and LLM Policy
Authors



Notes
- 1Anthropic).
- 2
- 3together